关于qemu逃逸的学习总结
前一段 VNCTF 2023 正好有一道非常入门 qemu 逃逸的题目,正好以此为契机进行 qemu 逃逸的入门学习,在这部分的学习中,要感谢 winmt 和 roderick 师傅解答我的一些困惑。
前置知识
QEMU与逃逸
QEMU 是纯软件实现的虚拟化模拟器,可以模拟多种不同的计算机系统和硬件设备。虽然 QEMU 可以模拟出硬件或虚拟环境,但它本质上只是一个程序,所谓 qemu 逃逸是指攻击者利用 QEMU 实现的有漏洞的 PCI 设备来获取主机的权限。从虚拟机中 “逃出来”,其利用方式和平常用户程序执行 system 函数是一样的,只不过平常 PWN 题的触发方式是通过用户的输入进行触发,而 QEMU 虚拟机的设备漏洞通过运行在虚拟机上的用户程序对设备的 IO 交互来间接触发。
PCI设备
PCI 设备是符合 PCI 总线标准的设备,设备可以申请两类地址空间,分别是 memory space 和 I/O space ,CPU 通过 memory space 访问设备 I/O 的方式称为 memory mapped I/O,也就是 MMIO。通过 I/O space 访问设备 I/O 的方式称为 port mapped I/O,即 PMIO。
MMIO
MMIO 是指将 I/O 设备的寄存器映射到系统内存地址空间中的一种机制 ,它使用相同的地址总线来处理内存和 I/O 设备,I/O 设备的内存和寄存器被映射到与之相关联的地址。当 CPU 访问某个内存地址时,它可能是物理内存,也可以是某个 I/O 设备的内存,用于访问内存的 CPU 指令也可来访问 I/O 设备。每个 I/O 设备监视 CPU 的地址总线,一旦 CPU 访问分配给它的地址,它就做出响应,将数据总线连接到需要访问的设备硬件寄存器。为了容纳 I/O设备,CPU 必须预留给I/O 一个地址区域,该地址区域不能给物理内存使用。
如果能理解上面所说的 MMIO ,那么就不得不提 xxx_mmio_read 和 xxx_mmio_write 这两个函数了( xxx 是设备名),xxx_mmio_read 函数用于从虚拟设备的 MMIO 地址空间中读取数据,而 xxx_mmio_write 函数则是向指定的 MMIO 地址空间中写入数据。qemu 会监听读写操作,当监听到读写后,就会调用这两个函数。
PMIO
PMIO 允许CPU通过专用的指令进行输入 输出操作,而不是将I/O设备视为内存中的特殊位置,在 PMIO 中,内存和 I/O 设备有各自的地址空间。 端口映射 I/O 通常使用一种特殊的 CPU 指令,专门执行 I/O 操作。在 Intel 的微处理器中,使用的指令是 IN 和 OUT。这些指令可以读/写 1,2,4 个字节(例如:outb, outw, outl)到 IO 设备上。I/O 设备有一个与内存不同的地址空间,为了实现地址空间的隔离,要么在 CPU 物理接口上增加一个 I/O 引脚,要么增加一条专用的 I/O 总线。
什么是QOM?
QOM (QEMU Object Model) 是 QEMU 的一个核心概念,它是 QEMU 在 C 的基础上自己实现了一套面向对象机制,支持多种体系结构和设备。在 QOM 中,每个设备都被表示为一个对象,对象有一个类型,该类型定义了设备的属性和行为。通过 QOM,开发者可以很方便地添加新的设备和扩展现有设备的功能,从而使 QEMU变得更加强大和灵活。
题目练习
escape_langlang_mountain
题目附件在 buu 的 vnctf 2023 的比赛里就有
简单分析
作为一名合格的菜鸡,刚开始连咋启动 qemu 都不知道,这里标明一下这俩文件。

如果有 qemu 的话,那么直接 ./launch.sh 就可以启动了。如果没有的话就 sudo apt install qemu-system 安装一下即可,如果还运行不了的话就 ldd 看一下是不是少什么库了,少哪个装哪个就行(具体做法可以参考文末的 奇奇怪怪的技能 部分 )
通过查看 launch.sh 文件我们可以知道设备的名称叫做 vn (如下)

接下来打开 ida 进行分析,正常的话看到的是多到让人懵逼的代码。
我们的思路是先定位到 vn_class_init 函数,因为去除了符号表,所以这里得根据特征来识别
我这里参考的是 winmt 师傅给我推荐的代码 QEMU educational PCI device ,下面所提到的特征都是根据对比这个模板来进行判断的
我个人认为这个 vn_class_init 一个显著特征就是有如下的 id

所以我们搜索 vn_class_init 字符串再结合下面这个特征来寻找 vn_class_init 函数,从而判断出来下面这个函数就是 vn_class_init 函数。
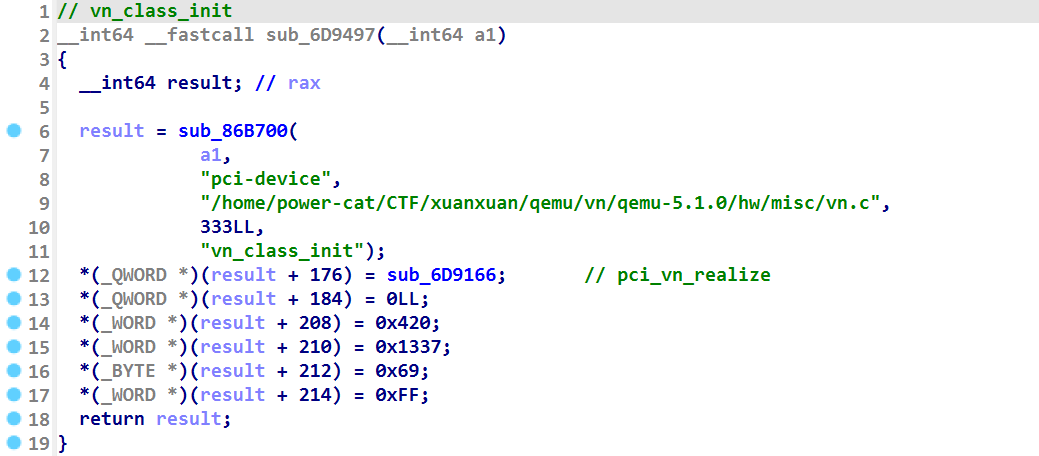
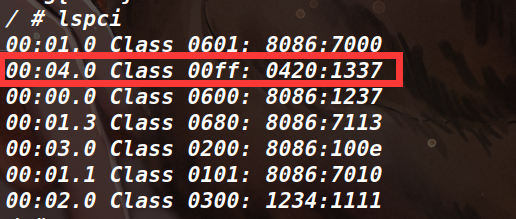
我们在本地启动 qemu 后,根据 lspci 命令得到的结果(比如出现的 0420 和 1337 )与上面 vn_class_init 函数中的 PCI 信息比较一下得知 vn 这个设备号是 04 (这个信息在写脚本的时候会用到)
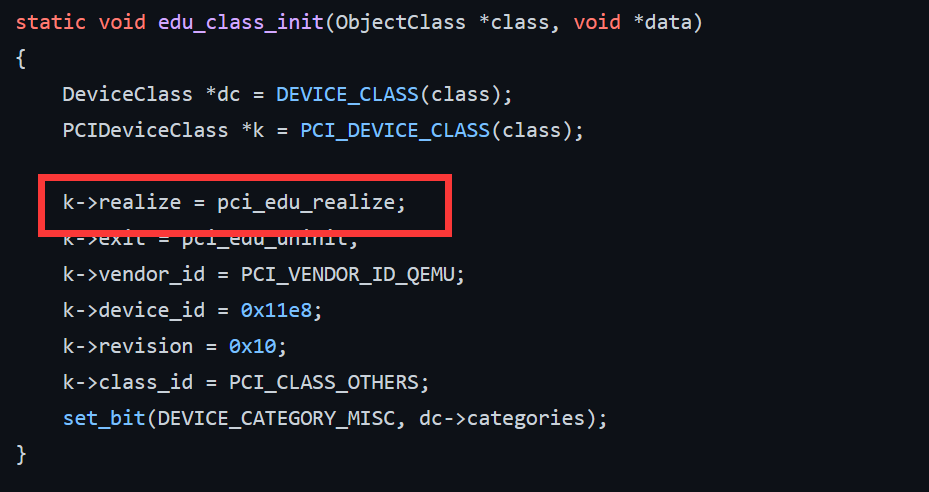
而之所以上面那里判断 sub_6d9166 为 pci_vn_realize 是因为模板代码中在 xxx_class_init 函数中这里有将 pci_xxx_realize 的函数地址赋值给结构体的成员变量(这些所谓的特征来判断,都是我自己的猜测,无法保证一定正确)
进入 pci_vn_realize 函数,我们这里可以继续对比模板代码(如下),猜测 sub_54ABB5 函数是 memory_region_init_io ,原因是这个函数出现了 vn_mmio 这个字符串,并且参数也符合 memory_region_init_io 的特征。
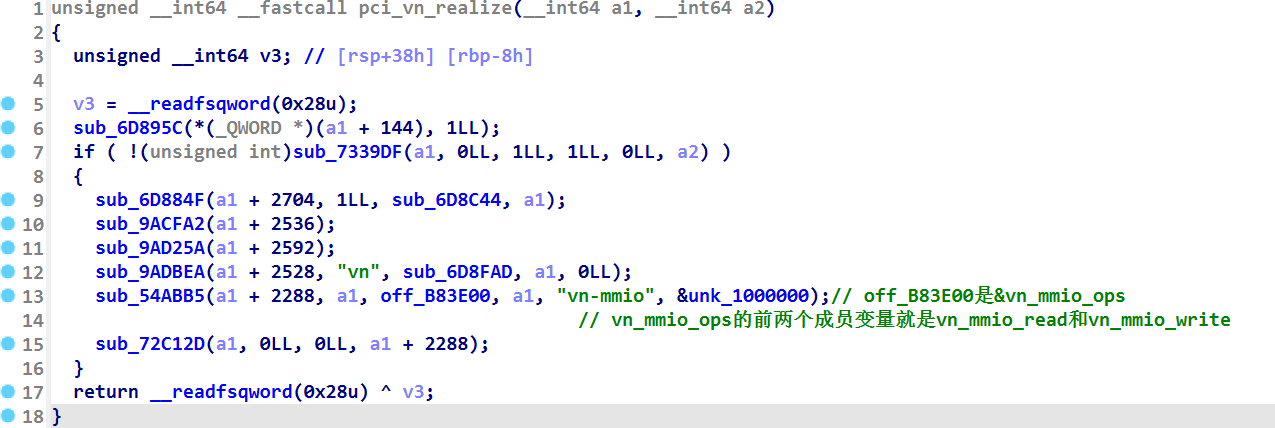
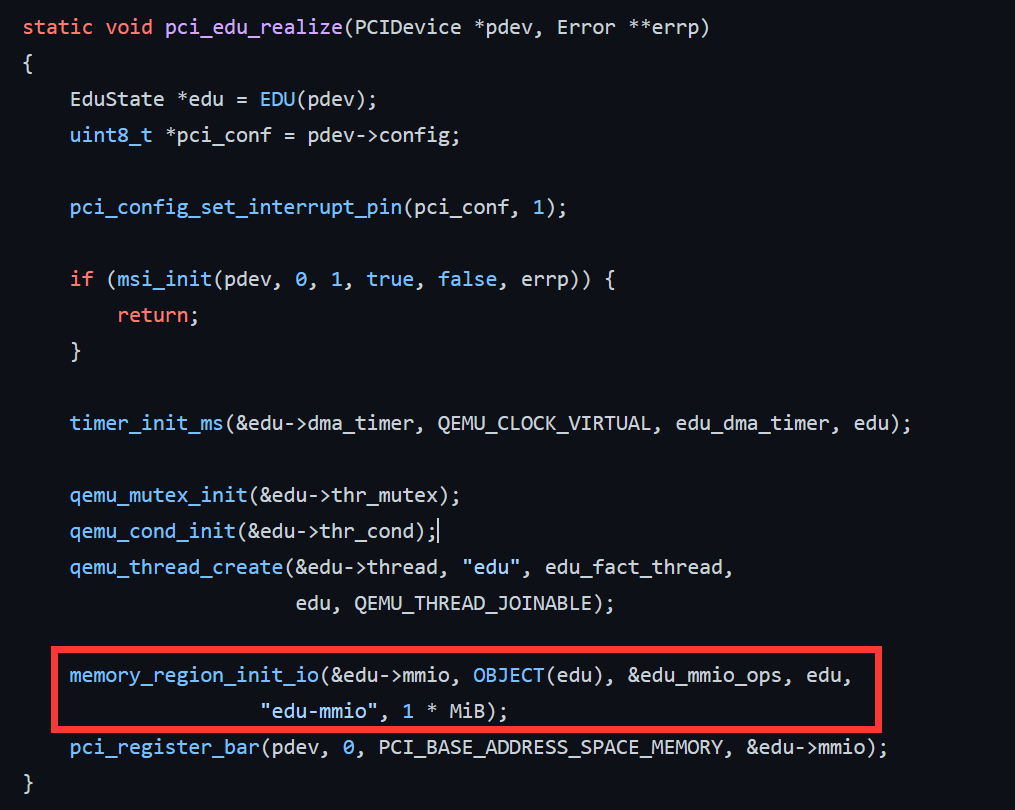
而 memory_region_init 函数的第三个参数,是 vn_mmio_ops ,它通常是用于访问 MMIO 寄存器的函数集合,这里面存放了 vn_mmio_read 和 vn_mmio_write 的函数指针(如下)

漏洞利用
我们再来看 vn_mmio_read 函数代码(如下)
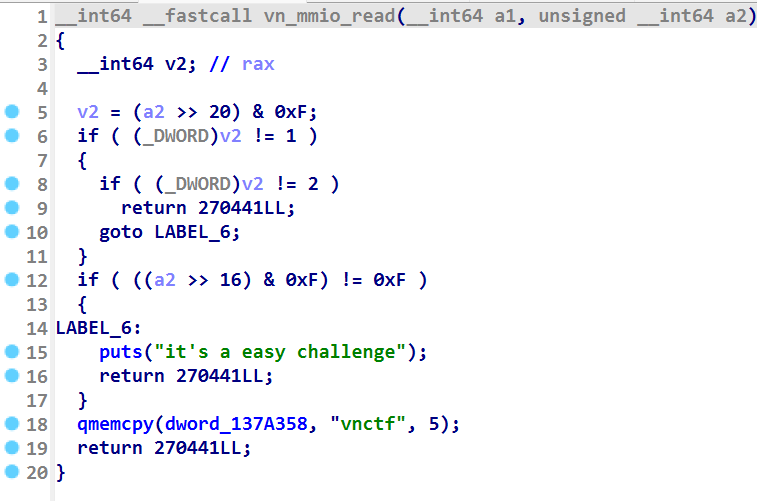
这个代码很短,如果 a2 满足 ((a2 >> 20) & 0xF) == 1 和 ((a2 >> 16) & 0xF) == 0xF ,那么就可以将字符串 vnctf 复制到 dword_137A358 的地址上。这里很明显是模拟了 mmio_read 函数的功能,即 MMIO 读取数据到 qemu 模拟的内存里,所以最后的 memcpy 函数就是在做这个,而 vnctf 字符串也就是要从 MMIO 里获取的数据。
再看 vn_mmio_write 函数代码(如下)
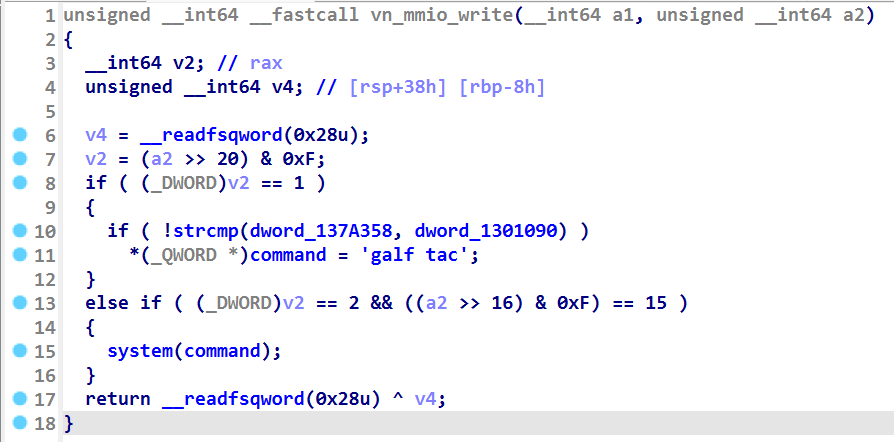
这里发现了后门函数,如果要触发 system 的话,需要让 a2 为 0x2f0000 (简单算一下就行),如果想让 command 为 cat flag 字符串的话,需要让 a2 为 0x100000 ,所以这个 vn_mmio_write 要执行两次。
EXP的编写
上面似乎一切都顺理成章,但我们好像忘记了,如何调用 vn_mmio_read 和 vn_mmio_write 函数并且控制他们的参数?
QEMU 实现 MMIO 模拟的其中一个因素就是监控虚拟机对 MMIO 内存的读写,触发对应的回调函数的执行。假设我现在对 MMIO 内存进行了读的操作,那么 qemu-system-x86_64 程序中的 vn_mmio_read 回调函数则会被触发,而它的参数,也就是读的 MMIO 地址。
所以我们可以编写一个 C 代码(如下),来对 MMIO 内存进行读的操作( mmio_mem 是 MMIO 区域的起始地址),之所以这段代码进行了读的操作是因为 return *(mmio_mem + addr) 将 MMIO 区域中的数据读了出来并返回。
uint64_t mmio_read(uint64_t addr) |
依次类推 mmio_write 函数是同理,向 MMIO 区域中写入数据,从而触发回调函数 vn_mmio_write ,这里的 value 无所谓,而 addr 则会当做参数传递给 vn_mmio_write
void mmio_write(uint64_t addr, uint64_t value) |
为了获取 MMIO 区域的首地址,我们需要打开其设备的 resource0 文件,使用 mmap 函数将其映射到用户空间上,最终实现了对 MMIO 区域的访问。还记得前面所说的设备号 04 么,接下来 open 的时候需要用到。
|
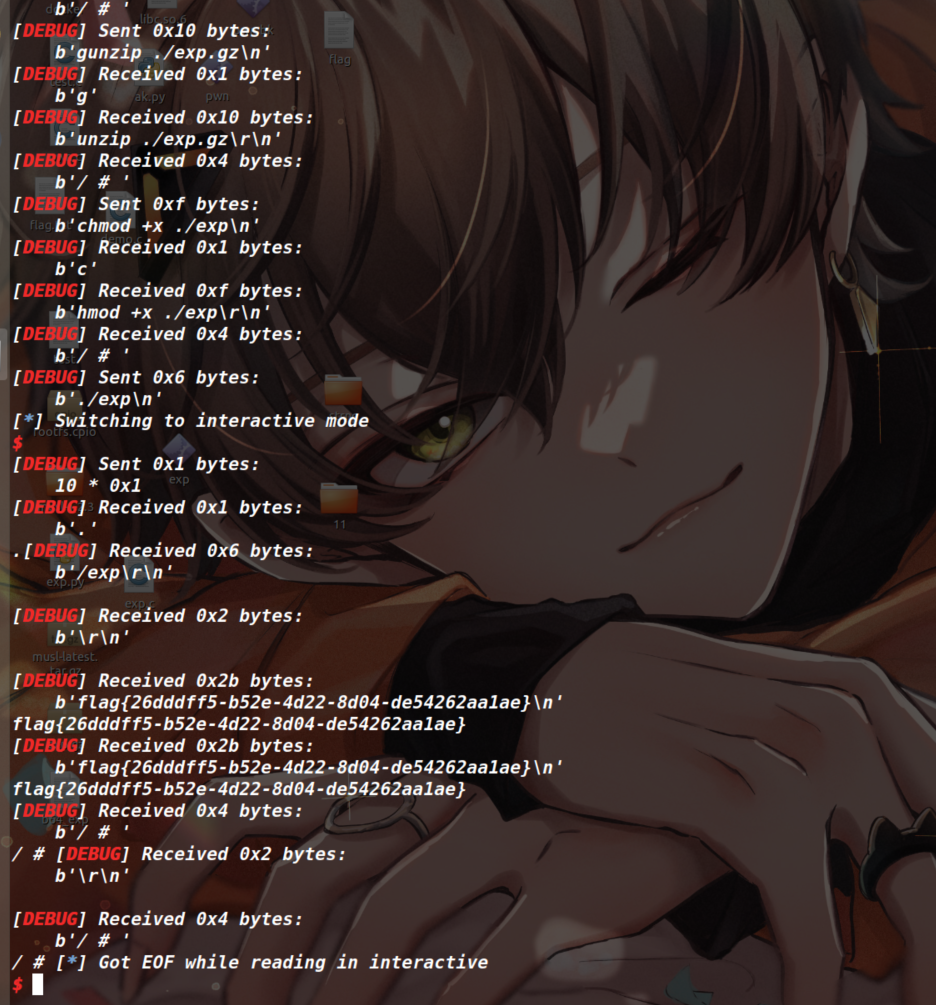
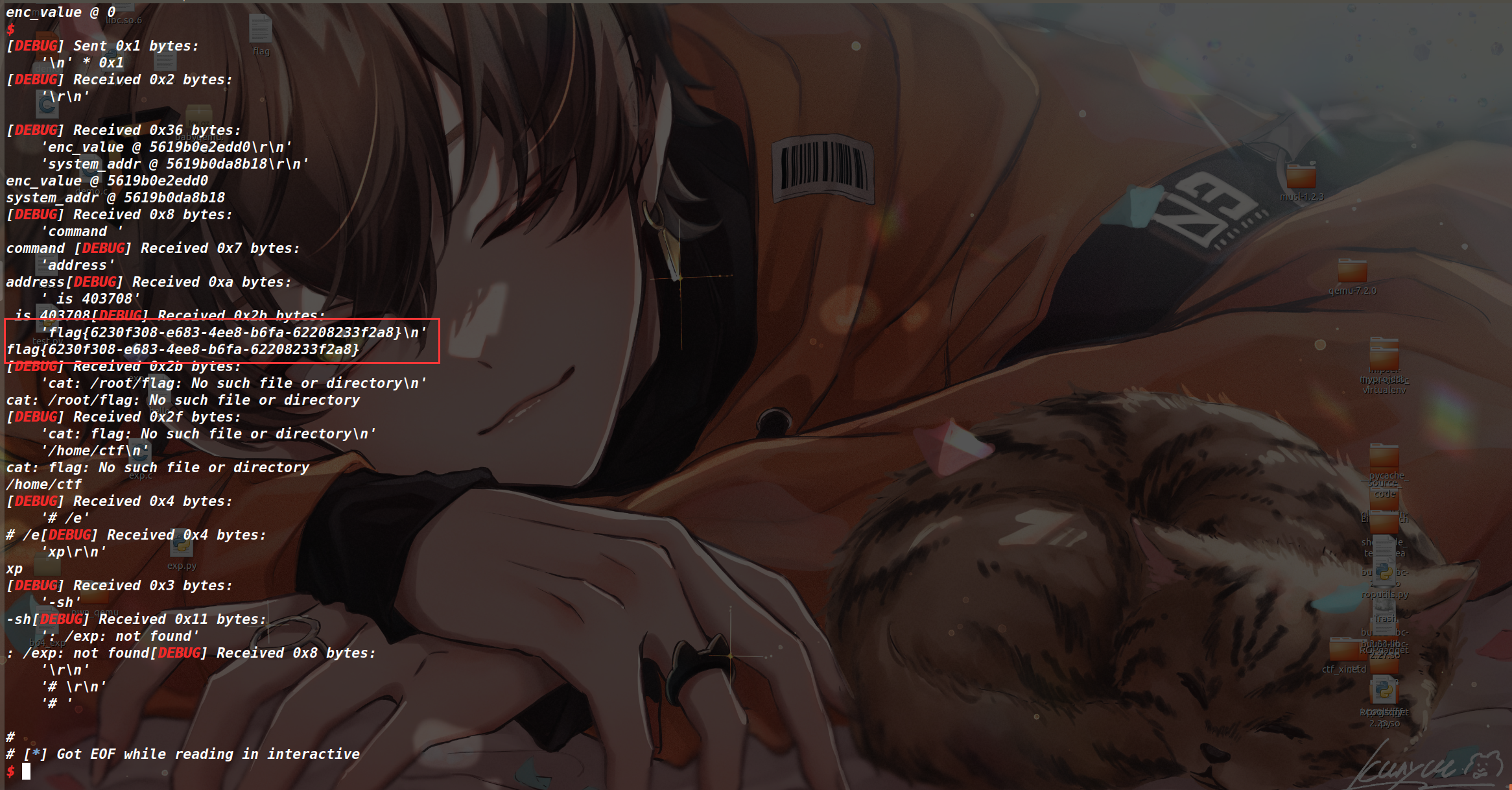
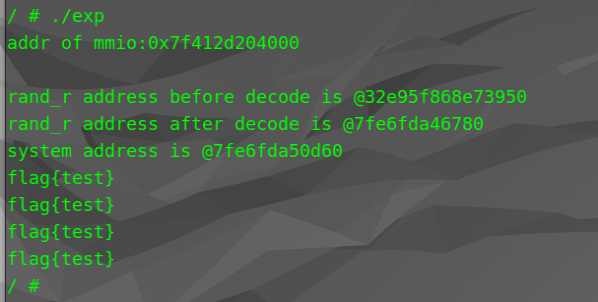
这个脚本是 winmt 师傅写的,整体思路就是先获取 MMIO 的起始地址,然后进行一次读,两次写的操作,以此来触发回调函数,最终触发了 system("cat flag") 。因为这个 qemu_system 程序还是跑在宿主机上的,所以在这个程序中执行 system("cat flag") 读取的是宿主机的 flag 从而完成的逃逸,这和 glibc 的题目获取 shell 其实一样,不过最初我以为这个 qemu_system 程序就是在 qemu 里面,所以执行了 system 也是在 qemu 里面所执行的。
上面这个脚本用 musl-gcc 所编译为静态链接的程序(用 musl-gcc 编译是因为这样生成的程序体积更小,静态链接的程序是因为远程环境有时候没有动态链接库)
编译命令为 musl-gcc exp.c -o exp -static ( musl-gcc 的编译与配置写到了文末 奇奇怪怪的技能 部分)
如果打远程的话,则需要使用上传脚本(如下,这依然是 winmt 师傅所编写的)
from pwn import * |
strng
这个的题目链接在 这里
然后启动脚本用这个 ,自己创建一个 launch.sh 文件就行(通过这个启动脚本可以发现,这个设备名叫做 strng)
./qemu-system-x86_64 \ |
启动之后,发现这模拟的是一个 ubuntu 虚拟机,然后登录的用户名是 ubuntu , 密码是 passw0rd 。
代码逆向
这个 qemu-system-x86_64 没有去除符号表,但是开了 PIE 。我们的逆向思路是去搜索函数名中存在 strng 字符串的函数,这样可以更快定位到关键函数。

我们从 strng_class_init 函数入手分析(如下),根据这里的数据可以分析出来设备号
如上,可以知道 strng 的设备为 00:03:0
然后来依次分析 strng_mmio_read strng_mmio_write strng_pmio_read strng_pmio_write 这四个函数,在分析之前,需要把这四个函数的第一个参数 opaque 的类型改为 STRNGState * ,这样可以让 ida 识别出来这个结构体,至于为什么这里要修改成 STRNGState * 类型,个人猜测可能这个位置正常的参数类型就是 xxxState * ( xxx 是设备名)
STRNGState 的结构体定义如下
typedef struct { |
strng_mmio_read 函数中如果满足 if 的话就返回 regs 数组里的值,
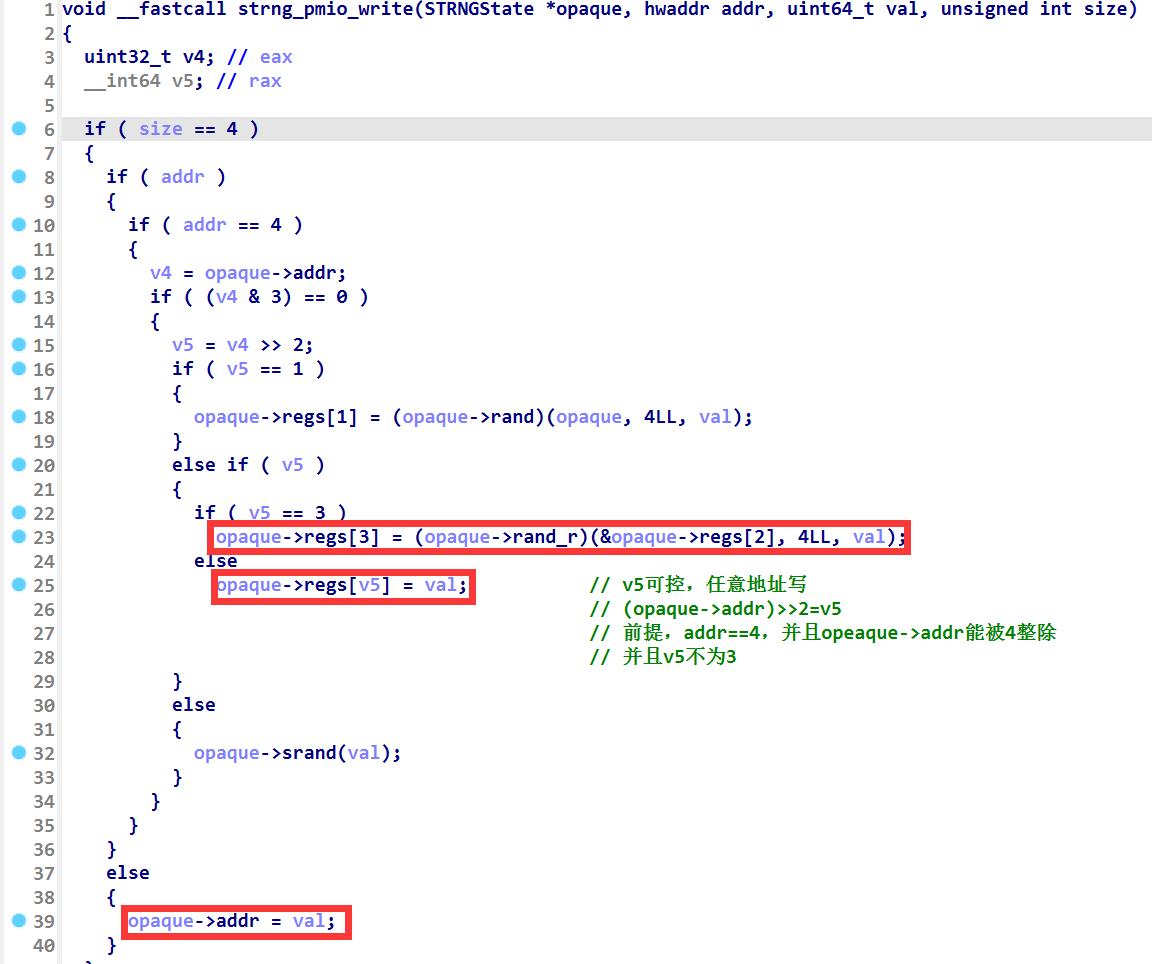
strng_mmio_write 函数是用 judge 做了三个选择,如果 judge 为 0 就执行结构体中的 srand(val) ,如果为 1 则执行 rand(),如果 judge 为 3 就执行 rand_r(&strng->regs[2]) 以及 regs[judge] = val ,否则的话 judge 存在但不为 3 ,就执行 regs[judge] = val。这里是存在一个 regs 数组的任意赋值的,索引和参数都可控
strng_pmio_read 函数存在一个任意地址读,以此来泄露结构体中 regs 数组下面的函数地址。正常来说的话 mmio_read 函数那里的任意地址读,也是可以完成的,但是实践了一下,一直没办法用 mmio_read 泄露出来 libc 数据
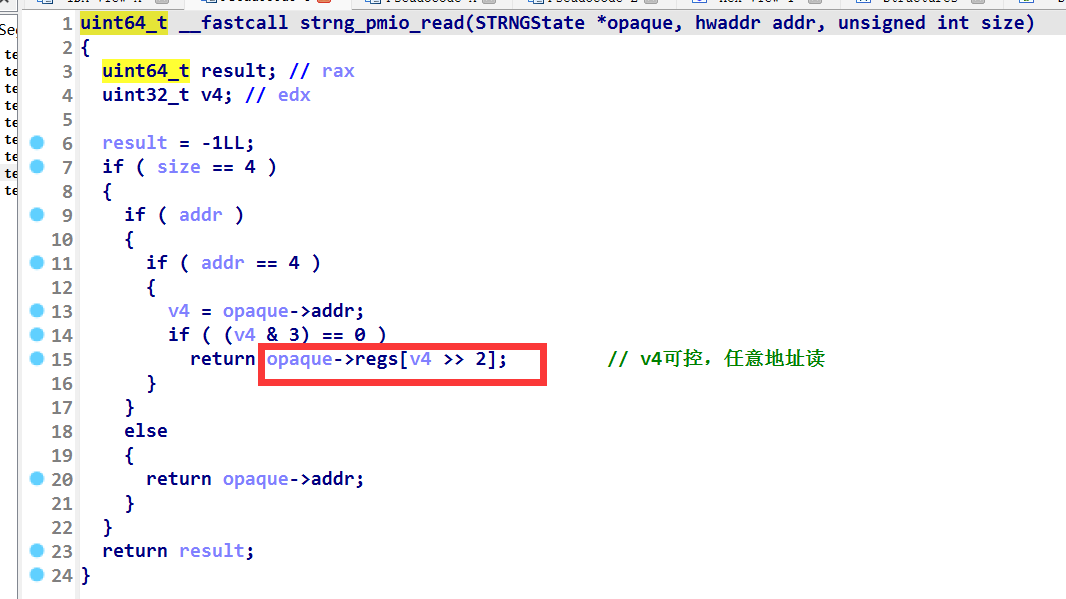
strng_pmio_write 函数最重要的有三个点,第一是 opaque->addr 可控,方便其他几个函数用这个 opaque->addr 进行利用 ,第二是 v5 为 3 的话,那么执行 rand_r 函数,并且参数为 opaque->regs[2] , v5 存在且不为 3 的话,可以利用 regs[v5]=val 实现任意地址写,并且这里的索引可以溢出(可能是因为这个 v5 是 opaque->addr 来确定的?)
利用思路
我们可以利用 strng_pmio_write 函数的任意写,来篡改 rand_r 这个函数指针,从而劫持程序的执行流,而这个函数的参数是 regs[2] ,我们可以利用 strng_mmio_write 函数来向 regs[2] 以及之后的内存单元写入数据(也就是布置我们的参数),泄露 libc 地址的话,可以用 strng_pmio_read 函数来进行泄露。
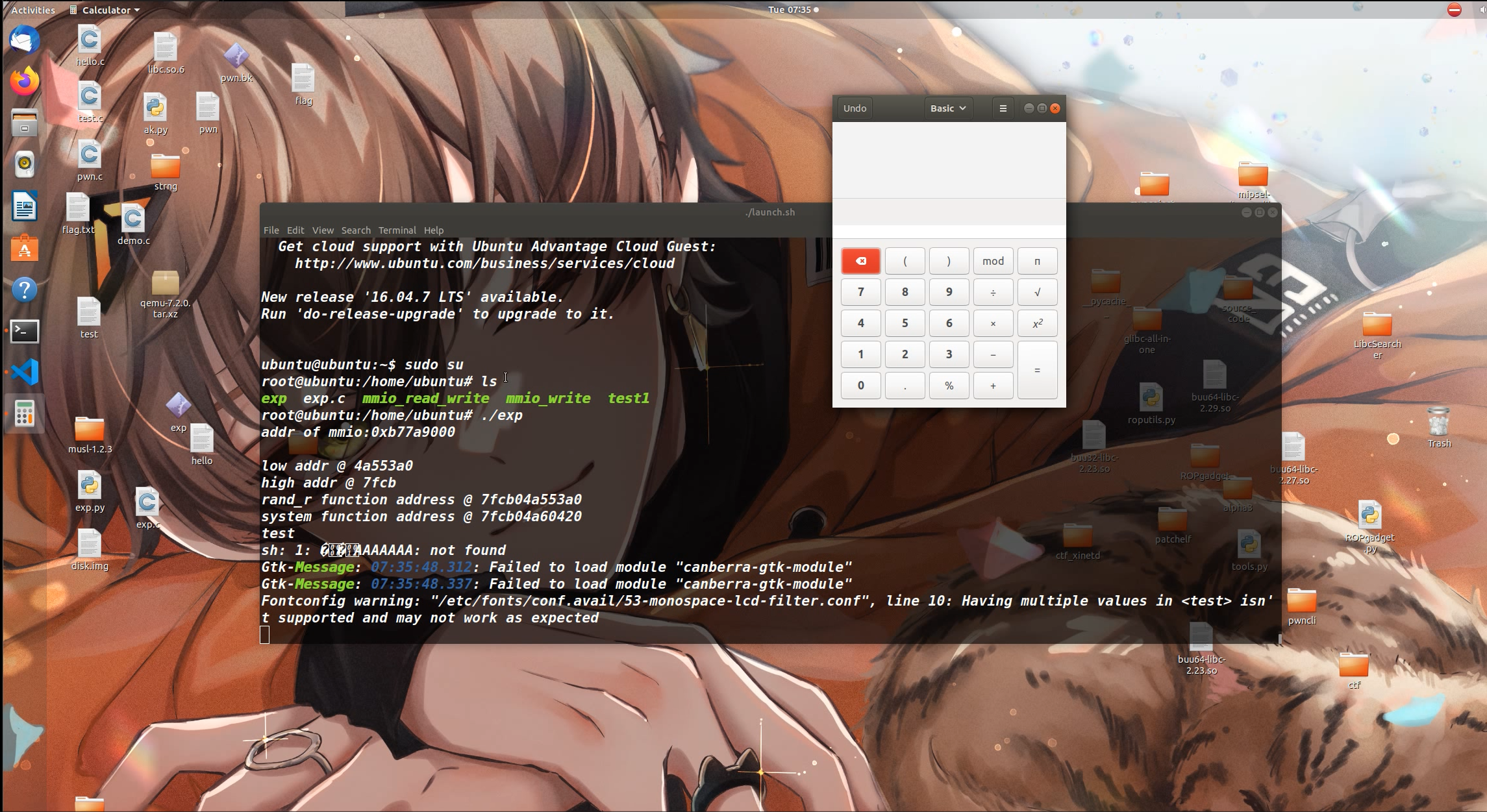
然后我这里采用的是弹一个计算器,其字符串为 gnome-calculator(执行/bin/sh 应该是没法交互的,可能反弹 shell 可以?)
补充:
PMIO_BASE 的地址查看命令是 lspci -v

EXP
|
猜测
因为上面发现 mmio_read 和 mmio_write 函数都无法索引溢出,尽管看起来 qemu-system-x86_64 程序中没有做任何的检查,但尝试了一下,数组越界访问的话确实是有点问题。然后看了一个师傅的解释,大概是下面的这个意思
MMIO 和 PMIO 的空间大小是由 pci_xxx_realize 函数中注册的。
本题这里标明了 MMIO 的大小是 0x100
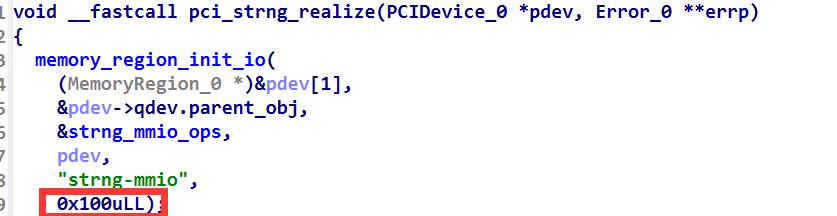
本地的 regs 数组大小就是 0x100 ,所以这里是无法通过数组溢出覆盖到下面的函数指针的。因为 pci 设备内部会进程检查
[HITB GSEC2017]BABYQEMU
附件在 buu 上可以搜到
通过分析 launch.sh 文件得知这次的设备叫做 hitb
#! /bin/sh |
我用的 ubuntu18.04 ,然后运行 launch.sh 的时候有如下报错

解决方法:执行 sudo apt install libcurl3
然后发现登录上去的时候询问用户名和密码
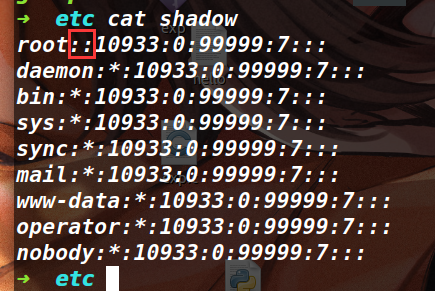
我们用如下命令,来将 rootfs.cpio 文件解压缩,然后我们去 etc 目录下,查看 shadow 文件
mkdir tmp |
发现如果用户名为 root 的话,后面的密码为空(如下)
因此在登录的时候,用户名输入为 root 即可登录成功(如下)
代码逆向
首先在 hitb_class_init 函数中确定设备号
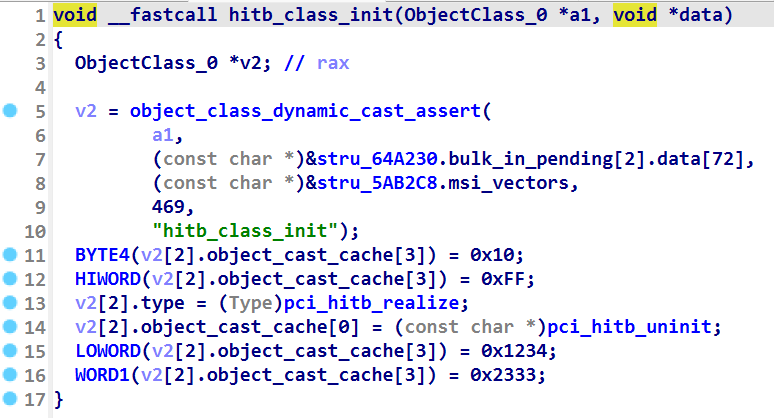
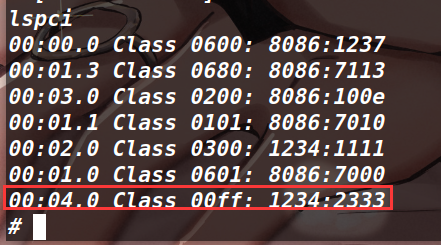
结合上面两个图片可以分析出 00:04:0 是 hitb 的设备号。
本题没有 pmio 的函数,但是有 mmio 的两个函数以及 dma_timer 。
简单分析下这三个函数
首先看 hitb_mmio_read 函数(如下)
这个比较明显,函数就是让你选择不同的 addr 然后用 return 返回结构体的不同字段。想显示结构体的字段的话,需要将 opaque 的类型改为 HitbState * (这是 qemu 逃逸的第三道题了,给我的感觉是通常漏洞都发生在数组索引越界上),这个 mmio_read 函数并没有用到索引来访问成员,所以这里简单看一下发现是没什么问题的。
其次是 hitb_mmio_write 函数(如下),这里就是让根据不同的 addr 然后给结构体不同的字段进行赋值,其值为 val。这里也没有通过数组的索引来访问成员,看起来也是安全的。
不过这里要关注一下 timer_mod 函数
该函数的大致意思是说当超过 expire_time 这个时间时会触发定时器中断,其处理函数是 ts 结构体中的 cb 参数指定的函数,在 pci_hitb_realize 函数中的 timer_init_tl 函数里面将 hitb_dma_timer 函数赋值给了 ts 结构体中的 cb ( call back )。因此我们添加 sleep 函数,让其超过 expire_time ,从而调用 hitb_dma_timer 函数
最后来看下 hitb_dma_timer 函数
这里就有我们心心念念的数组索引了,而且我们能够发现这里的索引 v2 是没有做任何检查的,并且它是被 opaque->dma.src 所控制,这个 dma.src 是在 hitb_mmio_write 函数可以被我们控制的,所以这里 dma_buf[v2] 是存在索引溢出的。
利用思路
重点看下 cpu_physical_memory_rw 函数
void cpu_physical_memory_rw(hwaddr addr, uint8_t *buf,int len, int is_write)函数是QEMU虚拟机监视器中一个用于读写物理内存的函数。该函数的作用是在虚拟机中读写指定地址的物理内存,并将读取或写入的数据存储在给定的缓冲区中。它的参数如下:
hwaddr addr:一个表示物理内存地址的无符号整数类型。需要读写的物理地址。uint8_t *buf:一个指向要读取或写入数据的缓冲区的指针。数据存储在这里。int len:一个整数,表示要读取或写入数据的长度。int is_write:一个整数,表示操作是读取(0)还是写入(非0)操作。
以这行代码为例 cpu_physical_memory_rw(opaque->dma.dst, cnt_low, opaque->dma.cnt, 1); ,其作用是将 cnt_low 写入物理内存 opaque->dma.dst 的位置( qemu 中的物理内存 ),写入的字节数为 opaque->dma.cnt 。
cnt_low 是由 (uint8_t *)&opaque->dma_buf[v2] 所赋值的,我们上面提到了 dma_buf 数组存在索引溢出,现在来看下比 dma_buf 低的位置有没有什么可用的(如下)
发现了 dma_buf 下面紧挨着的就是 enc 这个函数地址,因此我们可以让 v2 溢出,让其 dma_buf[v2] 指向 enc ,接着执行 cpu_physical_memory_rw 函数,这样 enc 函数的地址就会被写入到 opaque->dma.dst 指向的内存,也就是说只要让 opaque->dma.dst 为我们能够访问的物理内存,执行完这个函数后,我们就可以通过打印这个物理内存所对应的变量就能获取程序基地址
搜索一下发现,本题是有 system 函数的,所以只要拿到程序里函数的地址,用固定偏移就可以得到 system 函数的地址。
**注意:cpu_physical_memory_rw 函数的第一个参数需要的是物理地址,所以需要将 qemu 中的虚拟内存转换为物理地址,具体转换的方法可以参考文末的 qemu 中的虚拟内存与物理内存部分 **
这里的 exp 如下
uint64_t enc_addr; |
这个 exp 先打印了我定义的 enc_addr 这个变量在 qemu 中的虚拟地址,以及在 qemu 中的物理地址,和变量本身的值。当执行完 cpu_physical_memory_rw 函数后再次打印 enc_addr 变量的值(如下)
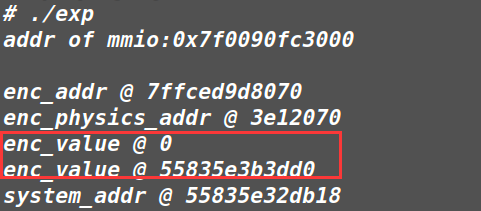
可以发现 enc_value 从最开始的 0 在 cpu_physical_memory_rw 函数执行后,变成了 0x55835e3b3dd0 ,这个地址正是 enc 函数的地址。从而说明了 cpu_physical_memory_rw 函数可以将一个值写入到我们指定的物理内存中
如果能理解上面这个将 enc 函数的地址读到物理地址上的过程,那依次类推,将物理地址中的数据写回 opaque->dma_buf[v2] 也就很好理解了。

值得一提的是,如果用 IDA 来看这个 v6 后面的赋值会感觉十分难理解,这里反而看汇编会更容易理解。
汇编部分如下

通过分析这四行汇编,发现上面给 v6 赋值的代码就是 opaque->dma_buf[opaque->dma.dst-0x40000]
所以控制 dma.dst 为 0x41000 ,此时就是 dma_buf[0x1000] 这个位置放的就是 enc 函数的地址,cpu_physical_memory_rw(opaque->dma.src, v6, opaque->dma.cnt, 0) 函数会将 opaque->dma.src 中的数据读入到 dma_buf[0x1000] 的位置,因为 dma.src 是物理内存地址,所以我们将 system 函数的物理地址写入 dma.src 。
最后我们依然利用一次 cpu_physical_memory_rw 函数来往虚拟地址中写参数(如下)
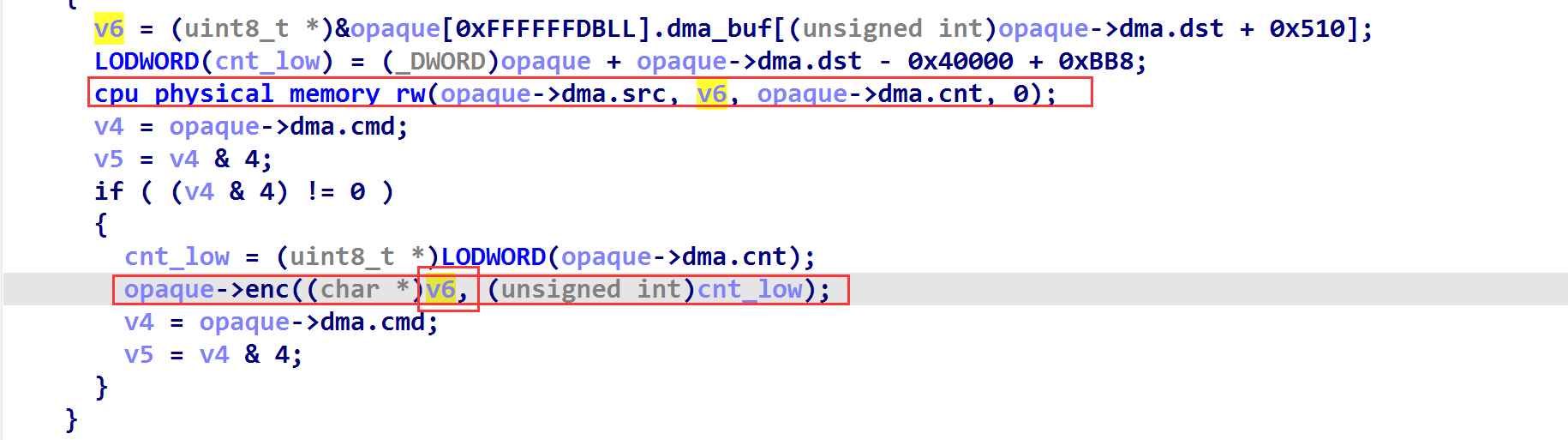
此时我们的 v6 要写为参数的地址,这回我们不需要数组索引溢出了,因此我选择了将参数写入到 opaque->dma_buf[0] 的位置,然后进入 (v4 & 4)!=0 这个分支,去调用 opaque->enc((char *)v6,cnt_low) 劫持执行流,调用 system("cat /flag")
EXP
|
d3dev
题目附件
链接: https://pan.baidu.com/s/1z1-Wk30RJEmQTSsEzVtvig?pwd=t9gp 提取码: t9gp
漏洞分析
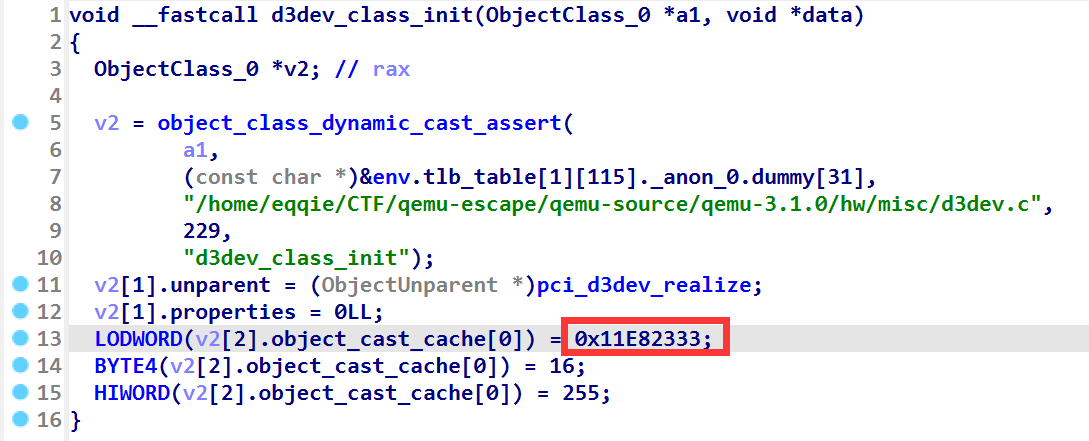
通过观察对比 class_init 函数中的数据,发现 d3dev 设备号为 00:03.0
数组索引溢出漏洞位于 d3dev_mmio_write 函数
这里的 v4 来自于 v4 = opaque->seek + (unsigned int)(addr >> 3);
seek 和 addr 都可控,也就意味着 v4 可控。这样我们就可以通过索引溢出来控制 rand_r 函数指针(如下),在 d3dev_pmio_write 函数中,调用了 rand_r 函数,如果将 rand_r 改成 system 函数,则可以触发后门。

需要注意的是如果使用 seek 默认为 0 ,那么addr 需要为 0x818 。但是 MMIO 区域为 0x800 ,因此使用 0x818 的话 PCI 设备在内部会检查到这里发生了越界(如下)。
所以这里还需要控制 seek 为 0x100 ,控制 addr 为 0x18 , 才能让 blocks[v4] 正好落在 rand_r 的位置。
泄露地址
因为本题开了 PIE ,即使程序中给了 system 函数,依然需要泄露程序的基地址。
泄露地址这里涉及一个 tea 加解密
这里是可以越界读取 rand_r 的地址,但是读取的结果会放到 v5 ,经过了 tea 加密后,最终 return 将其返回,此处的 key[0] key[1] key[2] key[3] 在 d3dev_pmio_write 函数中都可以被设置为 0 (如下)

因此最后的解密脚本应该如下
void decode(uint32_t v[2]){ |
这样将接收到的密文用这个函数解密,即可得到 rand_r 函数的地址。
用 mmio_write 函数写入 system 地址的时候,需要先加密后写入,不然只能写入四个字节。
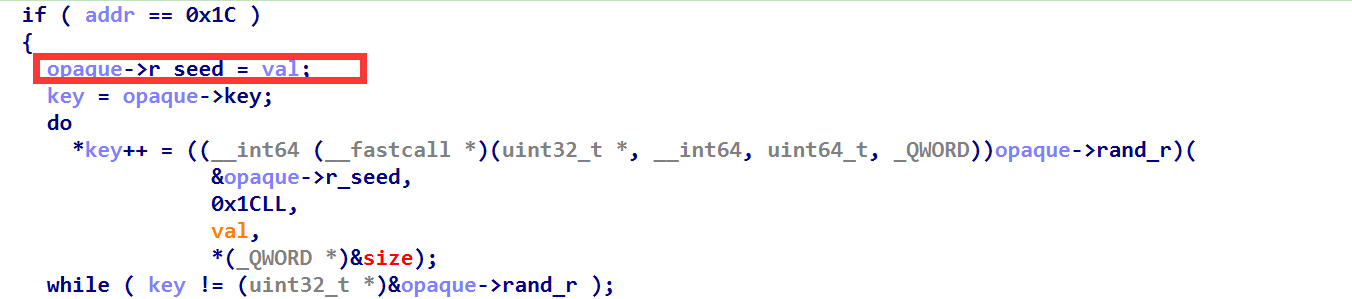
最后控制参数的话,假设我们想执行 cat flag 这个命令,那么需要把 r_seed 设置为 cat ,因为 r_seed 的大小就为四字节,所以只能存放 cat ,而 r_seed 下面的数据就是 blocks ,所以在 blocks[0] 的位置存放字符串 flag
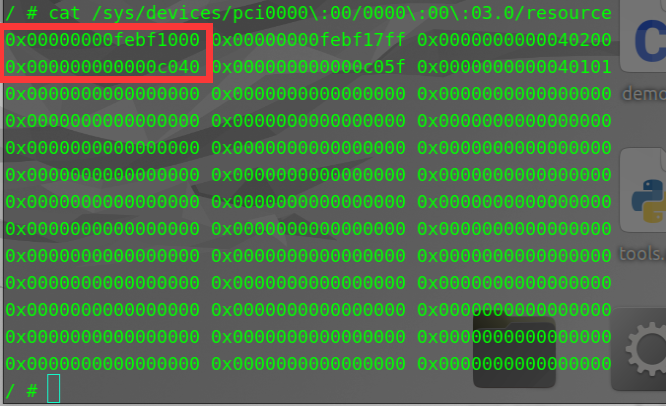
执行 cat /sys/devices/pci0000\:00/0000\:00\:03.0/resource 命令,获取 0xfebf1000 为 MMIO 基地址,0xc040 为 PMIO 基地址
EXP
|
奇奇怪怪的技能
调试
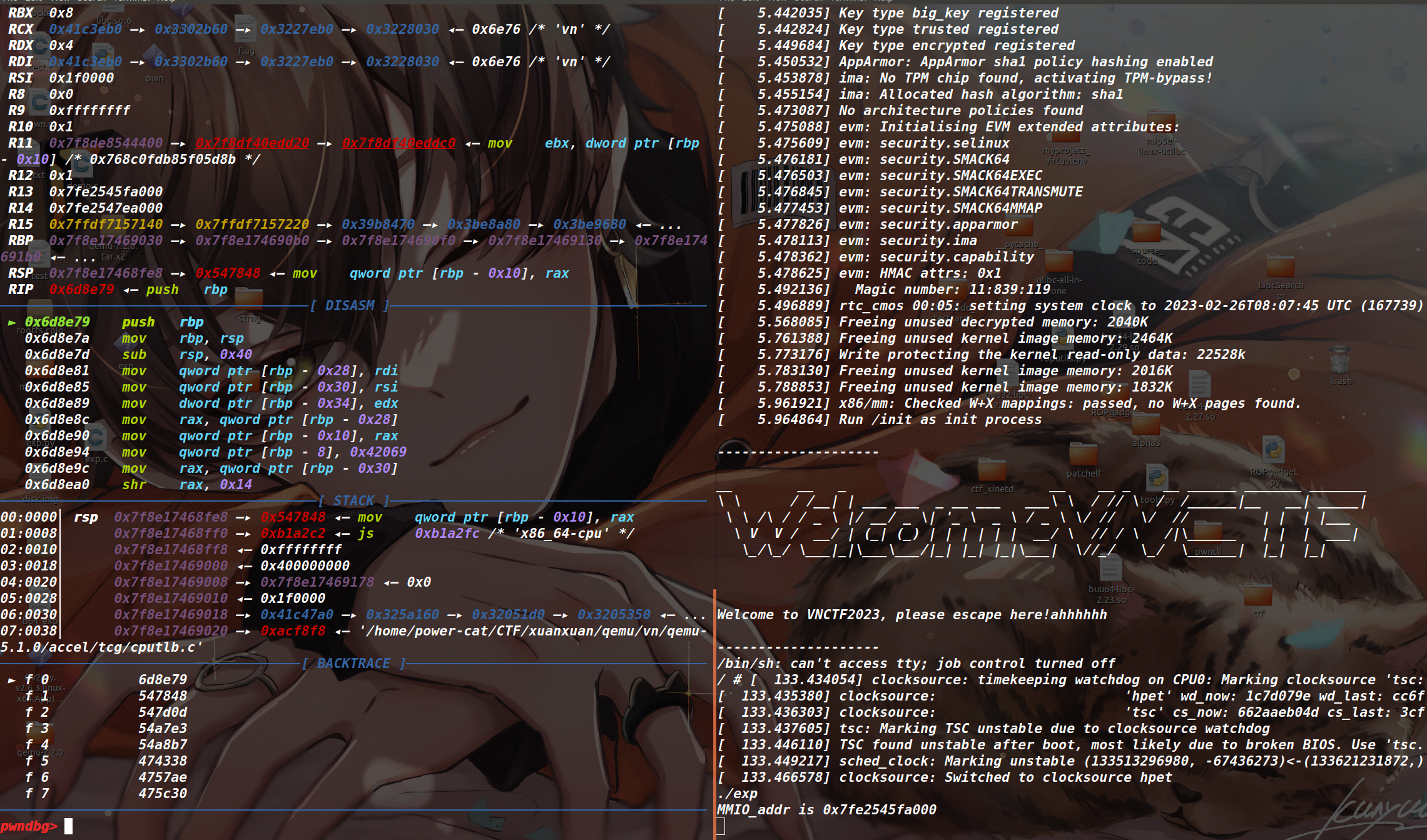
执行 launch.sh 脚本,将 qemu 启动起来,然后用 ps -a | grep qemu 来查看 qemu 的进程号,接着 sudo gdb qemu-system-x86_64 来开 gdb ,再输入 attach pid 附加进程开始调试(如下)
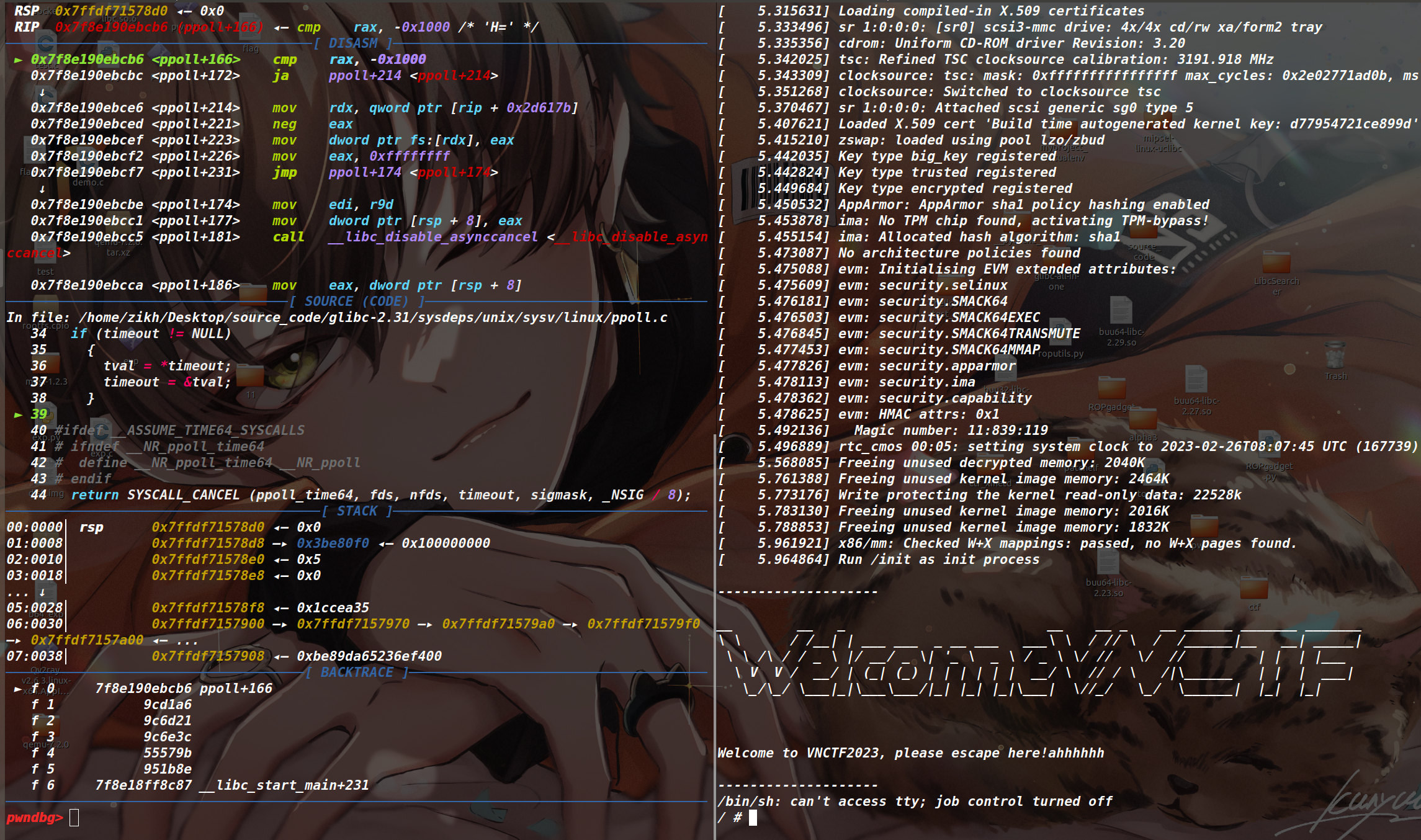
假设我们现在想从 qemu-system 中的 vn_mmio_read 函数这里开始调试,那么我们下该函数的断点(本题的 qemu-system 并没有开 PIE ,所以直接下断点即可,如果开 PIE 的话别忘记加基地址),并在 qemu 中运行 exp (如下),从而来调试查看我们关注的信息
qemu中的虚拟内存与物理内存
在这之前要先明白两点,第一点是客户机 指的是运行在虚拟机中的操作系统及其应用程序。而宿主机 则指的是运行虚拟机的物理机 。第二,qemu 跑在宿主机里,本质上就是一个进程,和其他进程没有任何区别
所以接下来有四个地址,分别是 客户机的物理地址,客户机的虚拟地址,宿主机的物理地址,宿主机的虚拟地址
宿主机的物理地址:指的是物理内存条上的地址,即硬件直接访问的物理地址。
宿主机的虚拟地址:操作系统所呈现给我们的虚假地址,它们被用来访问宿主机上的进程
客户机的物理地址:由
qemu程序执行了mmap函数,映射了一片内存空间出来,作为客户机的物理地址客户机的虚拟地址:客户机里的操作系统将刚刚映射出来的那片内存空间经过转换,呈现给我们了一个虚假地址
此时如果再去仔细分析下面这个图 (来自 https://bbs.kanxue.com/thread-265501.htm ) 的话,就大概能体会到这些地址直接的关系了
Guest' processes |
虚拟地址转换物理地址的过程
然后简单说一下将虚拟地址转换为物理地址的思路
每个进程都有自己的页表(存储在 /proc/self/pagemap 文件中),页表由一个或多个页表项组成,每个页表项记录了一个虚拟页到物理页的映射关系,在 64 位 Linux 系统中,页表项为 64 位。
现在给出一个虚拟地址,将其右移 9 位的话,得到的是页表项偏移量(页表项在页表中的偏移),这里 & ~7 是将页表项偏移量向下对齐到8字节边界上(因为页表项是八字节,这里是要八字节对齐)
offset = (addr >> 9) & ~7 |
得到页表项偏移量之后,我们就可以去用 lseek 和 read 函数从 pagemap 文件中读取一个页表项的信息,读取出来的信息包括:
bit 0-54 存储物理页帧号
bit 55-62 为保留位
bit 63 存储页面是否存在
如果存储页面存在的话,那我们就读取它的物理页帧号,最终要获取物理的地址的话,需要物理页帧号和页面内偏移量(虚拟地址将其右移
12位),因此我们最后的物理地址是将物理页帧号左移12位,将其或(|)上页面内偏移量,即可得到物理地址。
程序验证
用网上其他师傅的一个程序来验证一下
|
将其编译后放入 qemu 中,调试一下。
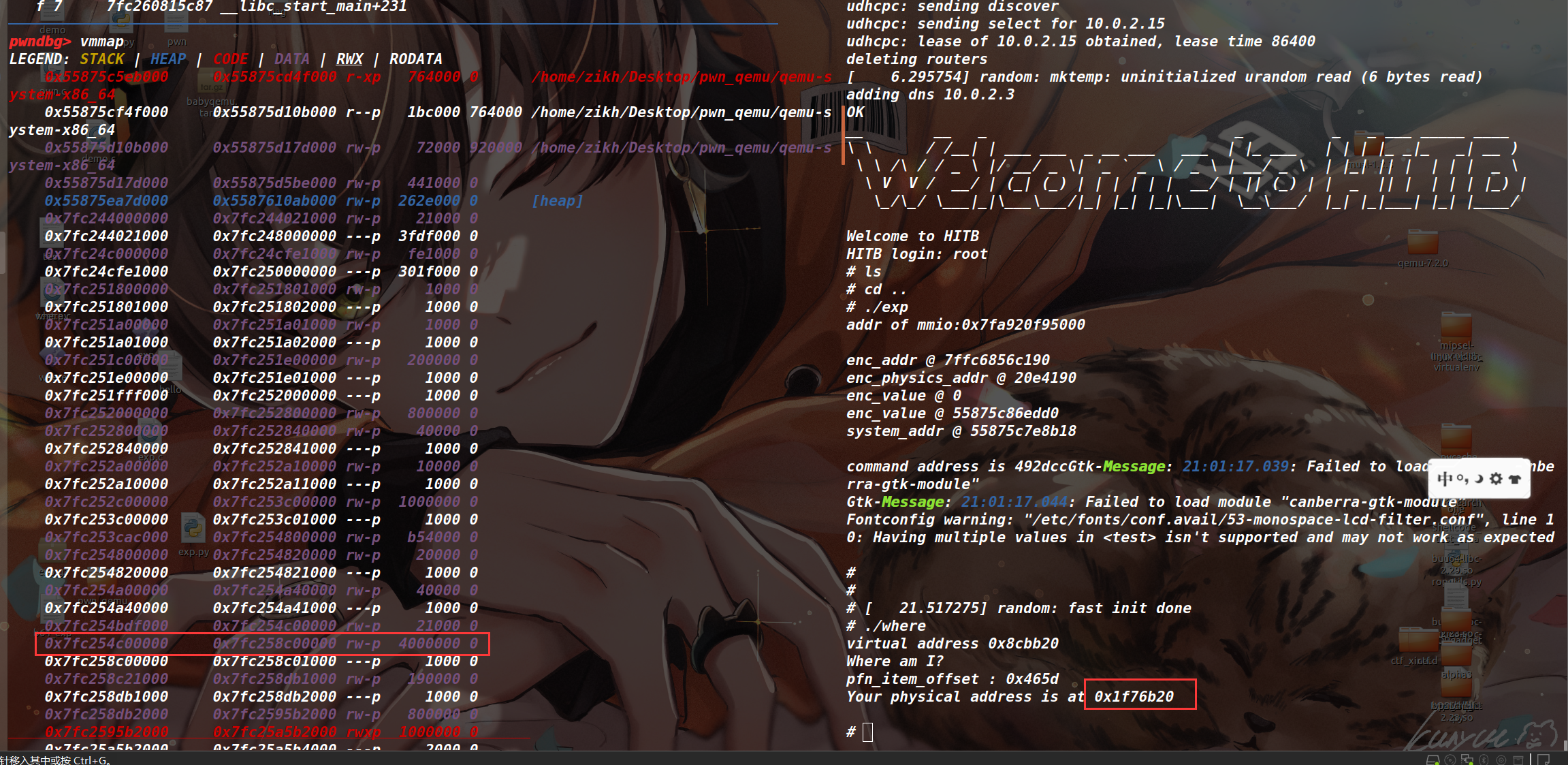
因为启 qemu 的时候,给的是 64M 的内存,所以我们去找这个 0x4000000 的起始内存地址,发现是 0x7fc254c00000 ,然后用这个地址加上物理内存,就能找到字符串 Where am I?

如果我们希望本地调试脚本,那么肯定是需要将 exp 文件放入到 qemu 中的,这里的通用方法是本地先将文件系统解包,然后把 exp.c 放进去,再打包即可,具体方法如下
解包和打包脚本
对 cpio 文件的打包和解包
解包脚本(如果缺少 unar 的话,请自行安装) 转自 https://www.jianshu.com/p/f08e34cf08ad 如下
!/bin/bash |
打包脚本
!/bin/sh |
将这两个脚本都放置到 /usr/local/bin 目录下,将解包脚本命名为 hen 打包脚本命名为 gen
最后别忘记给它们可执行权限
使用方法:
使用 hen rootfs.cpio 命令会在当前目录生成一个 core 文件夹,然后 cd core ,将准备编译好的 exp 文件复制进来。然后在 core 目录执行 gen rootfs.cpio 命令即可(注意,解包命令是在 core 文件的上一级使用的,打包命令是在 core 文件中使用的)
最后重新运行 launch.sh ,进入到 qemu 中后,就可以看到 exp 文件了。
对 img 文件的打包和解包
如果是 rootfs.img 文件的话,就创建一个 rootfs 文件夹,然后将 rootfs.img 文件复制进去,执行命令 cpio -ivmd < rootfs.img ,解包后,将 exp 复制到 rootfs 文件夹中,然后执行命令(在 rootfs 文件中执行) find . | cpio -o -H newc | gzip -9 > ../rootfs.img 即可将 exp 打包进去。
musl-gcc 的编译与环境变量的配置
wget https://www.musl-libc.org/releases/musl-latest.tar.gz |
然后 cd 进入解压之后的目录,执行下面的命令
./configure |
注意命令执行的权限
接下来,如果你能用绝对路径来执行 musl-gcc 那就说明安装的没问题,然后来配置环境变量
如果你和我一样使用的是 zsh shell (在命令行中输入 echo $0 可以进行确认),那么应该将环境变量设置添加到 ~/.zshrc 文件中
将下面的命令添加到 ~/.zshrc 文件的末尾
if [ -d "/usr/local/musl/bin" ] ; then |
然后使用下面的命令,重新加载 .zshrc 文件即可(此时输入 musl-gcc 就可以正常使用了)
source ~/.zshrc |
缺少库 报错解决
最开始在 ubuntu 18.04 上运行发现缺少库,然后 ldd 看了一下(情况如下)

这应该是 libc 版本太低导致的,于是我就改用了 22.04
此时的报错如下

然后 winmt 师傅教我的解决思路是 apt search xxx 来搜索缺少的库, xxx 则是 so 前面的数据,也就是 libbrlapi(效果如下)
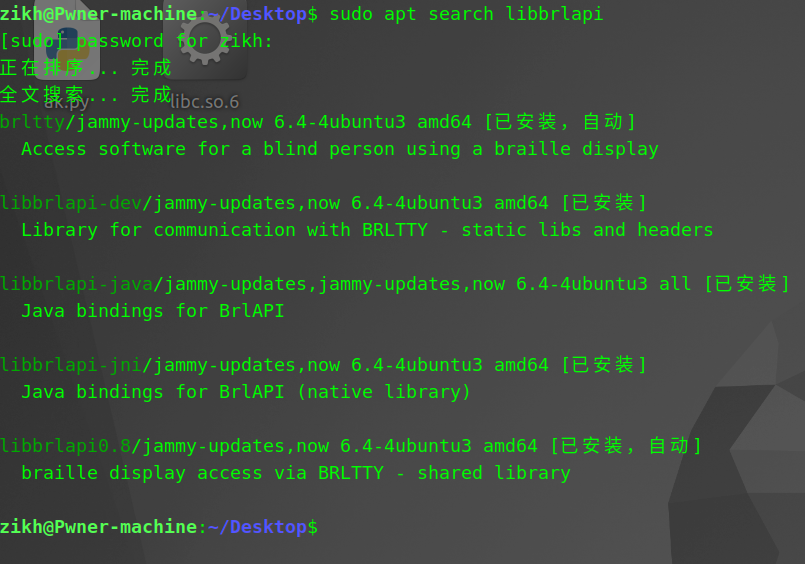
然后我是把这几个库全给安装了 ,命令是 sudo apt install xxx
不过发现依然是这个报错,于是执行命令 find /usr/lib -name "libbrlapi*" 效果如下

可以发现,现在的 /usr/lib 目录下是安装了 /usr/lib/x86_64-linux-gnu/libbrlapi.so.0.8 ,但是这个 qemu-system-x86_64 需要的是 libbrlapi.so.0.7 ,于是按照 winmt 师傅所说,创建了一个名字叫做 libbrlapi.so.0.7 的软链接,命令是 sudo ln -s libbrlapi.so.0.8 libbrlapi.so.0.7 ,最终问题解决,可以成功启动 qemu。
总结: 遇见这种少库的思路就是先 apt search 看一下少的库,然后少哪个安哪个即可,如果安装之后还少库,那么可能是按照的版本不对,创建一个软链接即可
参考文章
[原创]QEMU逃逸初探-二进制漏洞-看雪论坛-安全社区|安全招聘|bbs.pediy.com (kanxue.com)
qemu-pwn-基础知识 « 平凡路上 (ray-cp.github.io)
(45条消息) qemu逃逸小识_mmio_write_xyzmpv的博客-CSDN博客
QEMU 逃逸 潦草笔记 | Clang裁缝店 (xuanxuanblingbling.github.io)