C++异常处理部分源码分析&&问题探究
前言
前几天在看雪上读了一篇关于 C++异常处理 的文章,写的通俗易懂,文章开始通过 demo 介绍了 try-catch 异常处理机制绕过 canary 检查。闲来无事也跟着 demo 做了一下,发现作者在原文中写到:
这里将返回地址填充成了
backdoor()函数里 try 代码块里的地址,它是一个范围,经测试能够成功利用的是一个左开右不确定的区间(x)
看到这里我不禁疑惑,这种简单的利用中也会存在 玄学 无法确定的东西吗?我对这个左开右不确定区间感到好奇,打算去研究一下,这个成功利用的区间到底是如何来的。
本文从 gcc 源码入手,去探究区间问题。随后还分析了 try-catch 异常处理机制中源代码是如何完成 栈展开(Stack Unwinding) 的(本文为了避免出现过多非关键代码😶🌫️,因此删减了一些代码。但阅读中最好同时参考 gcc 源码,否则理解上可能有一些障碍)。
区间问题探究
本文分析的 gcc 源码版本为 11.4.0 ,下载命令 wget https://ftp.gnu.org/gnu/gcc/gcc-11.4.0/gcc-11.4.0.tar.xz
本文仅仅是在 ve1kcon 师傅写的 分享一次 C++ PWN 出题经历——深入研究异常处理机制 文章中进行了研究,所以 demo 也依然使用的是文章里开始的 demo。(避免调试的时候进函数的延迟绑定,可以再加编译命令 -z now),编译的环境是 Ubuntu22.04 GCC 版本11.4.0。
// exception.cpp |
对于ve1kcon师傅提到的 第二种利用方式 ,我编写了 EXP如下。
from pwn import * |
显然 0x401297 是劫持的返回地址,而 0x404070 填充的是 rbp(任意能够解引用的指针都可以)。通过不断修改劫持的返回地址,能够发现能够正常执行后门函数的地址区间为 [0x401293-0x401297]。除此之外,填充其它地址都会报错 terminate called after throwing an instance of 'char const*'。即使在这个返回地址的位置写入一个非法内存地址,程序也并不会因此发生段错误。尽管现在通过测试得到了区间,但为了搞明白这个区间具体是怎么得到的,下面来分析源码。
探索区间
具体针对区间做检查的函数是 __gxx_personality_v0 ,它位于 libstdc++-v3/libsupc++/eh_personality.cc 文件。下面删减了大量代码,后面讨论栈展开过程时会再具体分析。
|
_Unwind_GetIPInfo 函数根据 context(context和fs结构体介绍在文末)获取 ip 和 ip_before_insn。
inline _Unwind_Ptr |
_Unwind_GetIPInfo 函数通过 context->ra 返回 ip(也就是当前函数的返回地址),以上面 demo 和 exp 为例,此处的 ip 应该是 0x401297。而 ip_before_insn 表示当前帧(context)是否为信号帧,如果不为信号帧, ip_before_insn 的值就为 0。这里并不是信号帧,通过调试也能看出。(正常情况下这里调试时没有函数符号的,需要重新编译一份有符号信息的 libgcc_s.so.1 库。当然了,没有符号也可以参考 so 库的二进制文件和源码来定位函数)
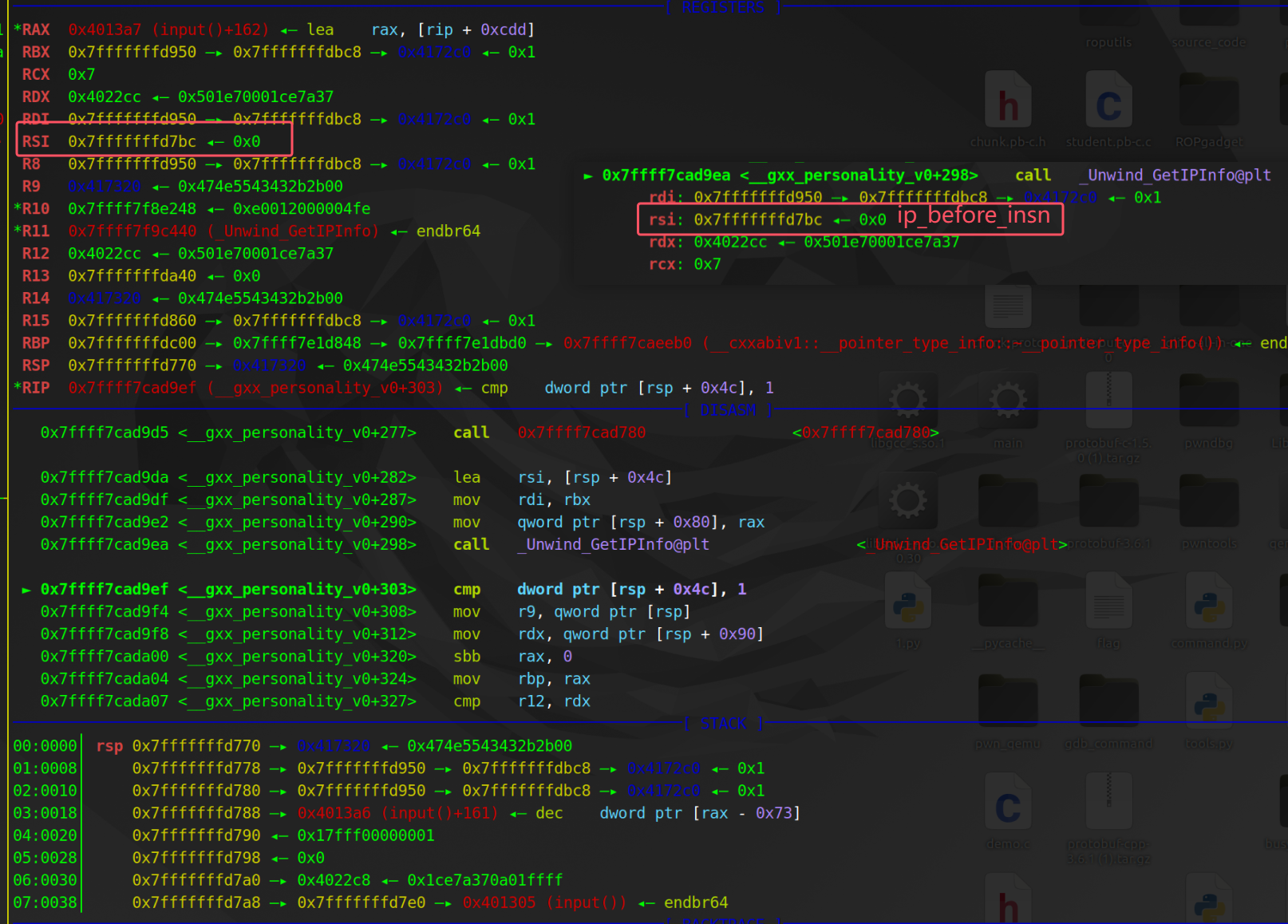
大部分情况下 ip_before_insn 都为 0 ,这样 ip 就会减一。但为什么要 --ip?如果一个指令的长度不为一字节,即使回退一字节也回不到上一条指令的起始地址。
if (! ip_before_insn) |
为了更好理解为什么要 --ip,我们来看下面的例子,这里的 try 范围是 [0x401305,0x401314] ,其中在 0x401305 处调用了 func1(其中的调用链为 main->func1->func2->func3,在 func3 中有 throw,其源码在 下文,这里不需要看源码)。当栈展开执行到 func1 的返回地址 0x40130A 处,如果没有 --ip 则会检测 0x40130A 是否位于合法区间。但此时地址 0x40130A 已经是抛出异常指令代码(异常是在 func1 函数中抛出的)的下一条指令了,它并不是实际抛出异常的指令,尽管这里抛出异常的下一条指令也位于 try 的范围中。
.text:0000000000401305 ; try { |
我们来看一个更极端的情况,在下面的第一个函数 func3 中 call ___cxa_throw 指令会抛出异常,它的地址是 0x4012D3。可这个地址恰好是 func3 函数的最后一条指令,在执行 call ___cxa_throw 时压栈会将下一条指令 endbr64(该指令是 func2 函数的),也就是 ___cxa_throw 函数的返回地址为 0x4012D8。若 func3 函数中有 try,无论如何位于 func2 里的 0x4012D8 地址也不会出现在 try 的区域 。可谁能保证抛出异常的指令不会是当前函数的最后一条指令呢,因此将返回地址(IP)减一就是最好的解决方案 。抛出异常指令的返回地址减一,一定是落在了抛出异常指令的范围内。异常展开表(LSDA、call-site表)是基于指令地址范围匹配的,只需确保IP重新落回那个指令的区间内,就能正确匹配到相应的call-site entry。
.text:00000000004012A5 ; __unwind { |
简单总结一下 --ip 的问题,我觉得异常处理需要检查的是抛出异常的指令,而 ip = _Unwind_GetIPInfo (context, &ip_before_insn); 获取的是抛出异常的下一条指令(其返回地址),为了检测区间一定正确,必须减去一个字节使得 IP 仍然属于抛出异常的那条指令范围。
下面来到了区间检查的代码处,这个 p 指针是 parse_lsda_header 函数的返回值,其指向了解析 LSDA 头部信息后的剩余数据指针(也就是Call Site Table)。因此 read_encoded_value (0, info.call_site_encoding, p, &cs_start) 就是从 Call Site Table 里面读取 cs_start,另外的 cs_len、cs_lp 同理。
while (p < info.action_table) |
但需要注意的是,在调试的时看不到 read_encoded_value 函数。因为使用了 inline 关键词修饰,只能看到展开的 read_encoded_value_with_base 和 base_of_encoded_value 函数(无符号)。
static inline const unsigned char * |
结合库文件 libstdc++ 配合参数特征能分辨出来下图中的 0x7ffff7cad780 是 base_of_encoded_value ,而 0x7ffff7cad4e0 则是 read_encoded_value_with_base 。
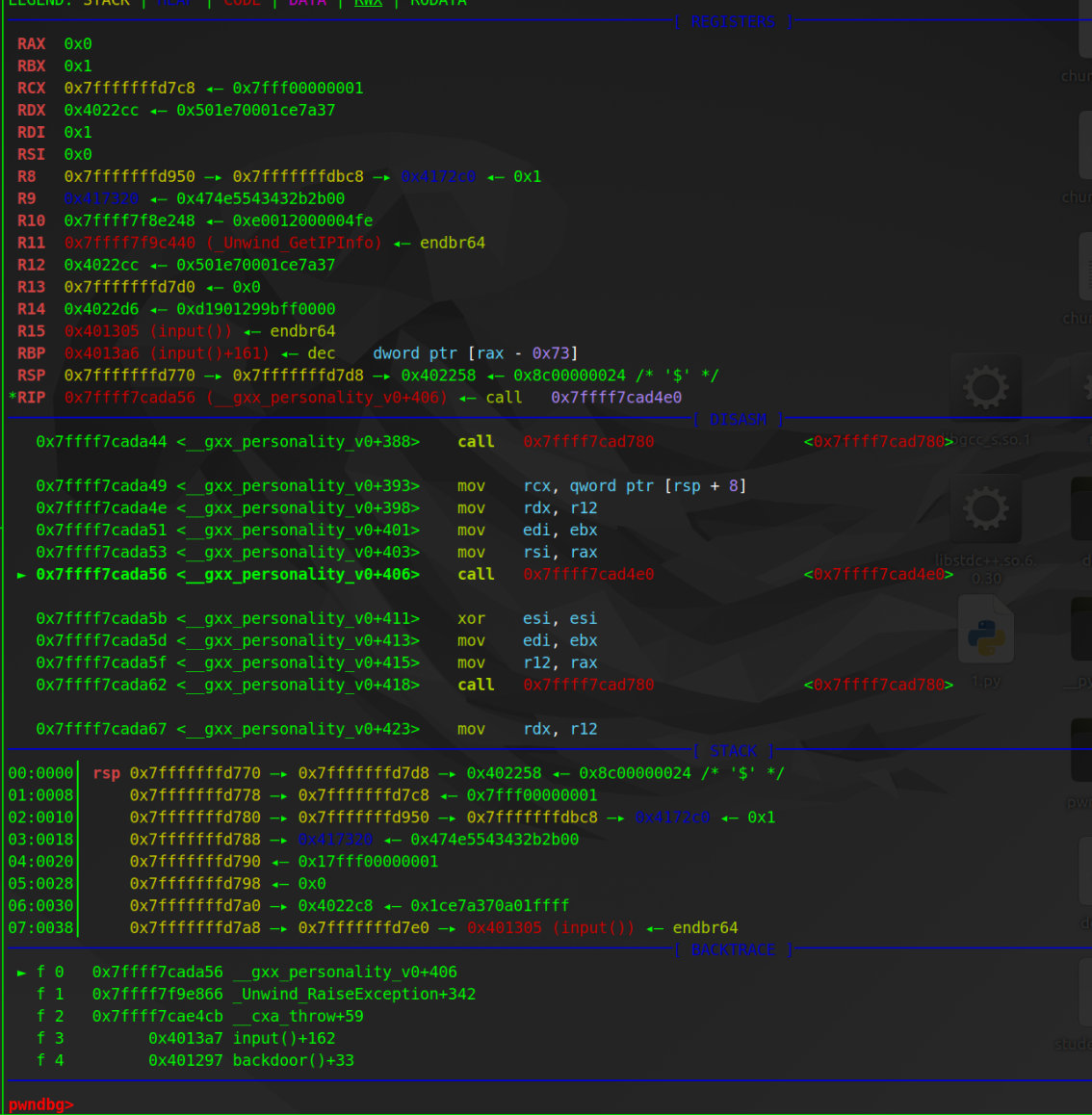
为了避免图片太多,这里直接给出三次 read_encoded_value 函数执行后的调试结果。
| 字段 | 含义 | 值 |
|---|---|---|
| cs_start | try的起始地址距离当前函数的偏移 | 0x1c |
| cs_len | try的范围 | 0x05 |
| cs_lp | catch的起始地址距离当前函数的偏移 | 0x23 |
那么确定 IP 的具体范围,只需要再获得 info.Start 即可。阅读源码得知 info.Start 就是 context->bases.func(含义是当前帧的函数起始地址)。此时因为替换了原本的返回地址为 backdoor 地址,导致栈展开保存上下文信息时的返回地址也更新为了 backdoor ,所以当前帧的函数起始地址就成了 0x401276(backdoor)。
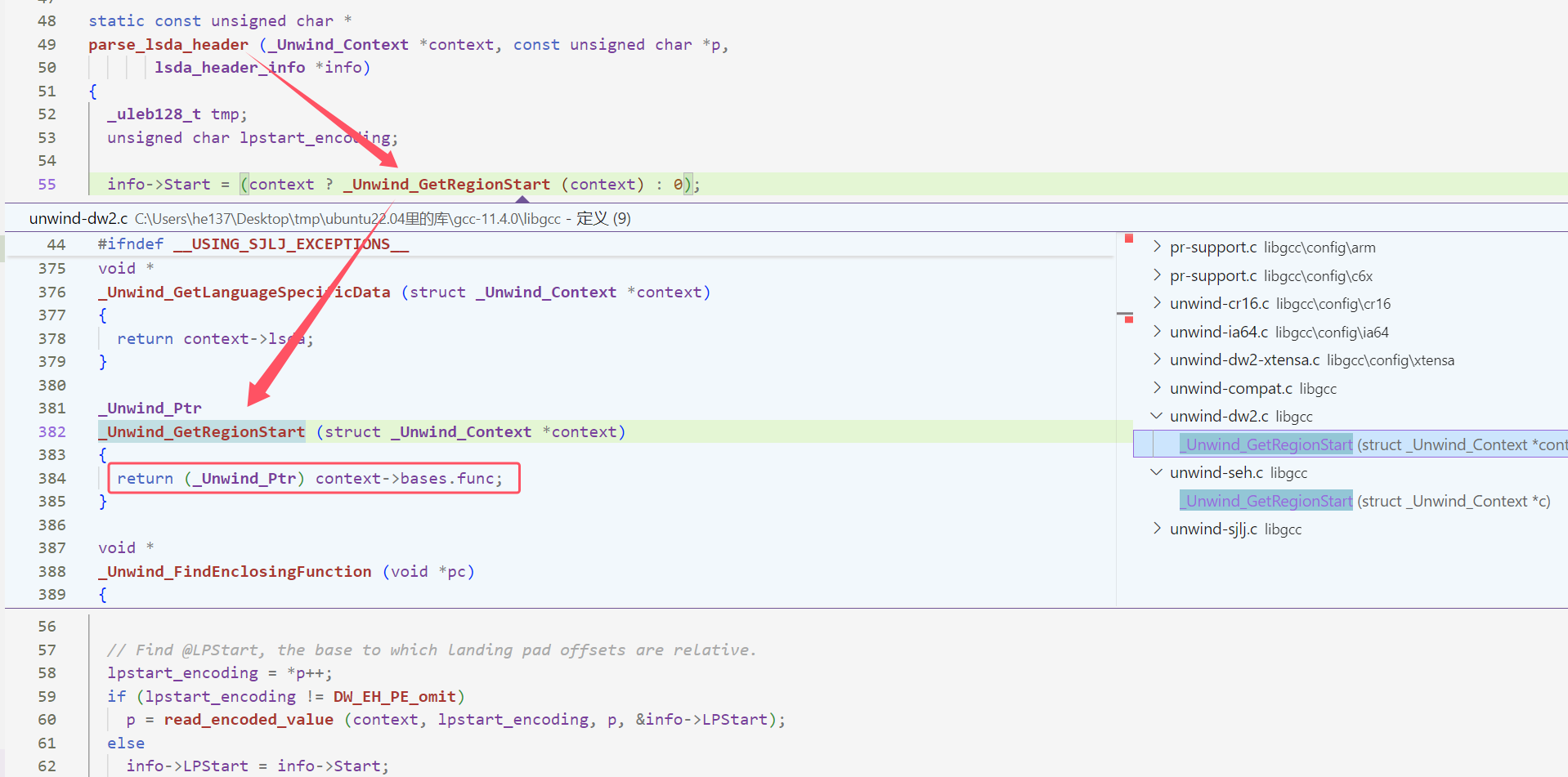
再来看下面的检查,带入上面得到的数据,实际上就是 info.Start + cs_start<= IP < info.Start + cs_start + cs_len。 info.Start + cs_start 求解的是当前函数 try 的起始地址, cs_len 则是 try 区间的实际长度。所以正常来说检查的抛出异常代码的返回地址范围就是 try 的区间,即 [0x401292,0x401297), 但因为存在 --ip 所以变成了(0x401292,0x401297] 。
if (ip < info.Start + cs_start) |
意外产生新的区间
上述获取 Call Site Table 中数据时,除了调试可以看到之外,还可以使用命令 readelf -x .gcc_except_table ./demo,能够获取 .gcc_except_table 节里面的数据,LSDA 就位于这个节中。LSDA Header 截止于 0x4022b0。因此 read_encoded_value 读取的 cs_start 、cs_len 、cs_lp 也就是下面的 1c 05 23,这一点在运行时就已经确定。
zikh@Pwner-machine:~/Desktop/tmp$ readelf -x .gcc_except_table ./demo |
值得一提的是,如果第一次针对 IP 的区间检查没有通过,while 循环会再来一轮。那么除去一个字节的 cs_action,下一轮的 cs_start 、cs_len 、cs_lp 分别为 30 05 00。可以发现在 info.Start 没有改变的情况下,此时产生了一个新的区间,那如果劫持返回地址满足这个区间能否跳转?
通过分析源代码是不行的,因为 cs_lp 取到的是 0x0,导致 landing_pad 是 0,触发了代码 if (found_type == found_nothing) CONTINUE_UNWINDING; 跳过了本次 __gxx_personality_v0 表示什么都没有搜索到。之后在 _Unwind_RaiseException 函数中继续更新 context 发现已经到了栈的最外层了依然没有找到 handler ,该函数返回并触发最后的 std::terminate ();。
初步分析的总结
最终再说回 C++异常处理绕过 canary,通过溢出的手段篡改了正常的函数返回地址。但因为 throw 抛出异常后,剩下的指令都不会再执行了,包括检查 canary 的代码,同样也不会通过 ret 的方式劫持到 backdoor 中。但是因为抛出异常后,会根据 CFI 和 FDE 进行栈展开。在这期间程序误把填充的 backdoor 地址当成栈展开的一个函数结点,并且 __gxx_personality_v0 还在这个函数结点中发现了十分合适的 handler,经过返回地址区间检查无误后,将执行流以及抛出异常时的上下文状态一起传送至了 backdoor 的 catch 部分。当然,上面举例的 demo 足够特殊,catch 出来正好就是个 system("/bin/sh"),否则这才是一个漏洞利用的开始😭。
总结 ve1kcon 师傅提到的第二种利用方式。首先可以控制栈里存放正常的函数返回地址,其次要跳转到的代码位置要位于 try 区间(设 try 起始地址为 X,那么代码地址必须位于 (x,end(x)]),最关键的是只能跳转到 catch 的代码且 catch 的类型还需要一致。而这仅仅是能劫持程序的执行流,并不意味着可以稳定后续控制。
C++异常处理栈展开源码分析
当上面的区间问题分析过之后,对于为什么溢出劫持掉返回地址就能完成指定代码跳转这个问题并没有探究。正常溢出利用是通过衔接 ret 指令( pop rip 弹出栈顶的指针作为下一条指令执行)控制执行流,而在上面总结中也简单提到了异常处理中篡改返回地址改变执行流是因为栈展开时到 backdoor 里也匹配到了一个 catch。
但我觉得这些还不够,程序到底是根据什么信息进行的栈展开? 为什么将返回地址改成 backdoor+33 ,info.Start 就变成了 backdoor?__gxx_personality_v0 函数在异常处理中起到了什么作用?在抛出异常后,栈展开具体是怎么做的?
为了搞清楚这些,我对 __cxa_throw 函数源码进行了分析(对一些源码进行了删减,如有需要请自行查看完整源码)。为了观察多次的栈展开,下面的演示将使用新的程序 unwind。
//g++ unwind.cpp -o unwind -no-pie -fPIC -z now -g |
在 __cxa_throw 函数(定义在 libstdc++-v3/libsupc++/eh_throw.cc)开始进行了初始化异常处理的元数据,并准备好异常对象用于栈展开和异常捕获过程。_Unwind_RaiseException 函数进行了具体栈展开操作,如果在此期间遇到了某些错误,则会调用 std::terminate 函数终止程序。
extern "C" void |
_Unwind_RaiseException 函数进行栈展开的策略分为了搜索阶段 (Phase 1: Search) 和 清理阶段(Phase 2: Clean) 。
搜索阶段:从抛出异常的函数开始检测当前函数(本文提到的当前函数表示cur_context所描述的函数)是否存在 catch 或者 cleanup(当前函数的收尾工作,比如当前函数中某实例的析构函数需要执行)。如果 catch 和 cleanup 都没有,就会通过 uw_frame_state_for 和 uw_update_context 函数回退到上一级函数(cur_context所描述的函数的父函数),将上一级函数上下文信息更新到 cur_context 中继续判断,直至遇到了 catch 或者 cleanup ,调用 personality routine(在本文中指的是 __gxx_personality_v0 函数)判断具体遇到的是哪种情况。如果遇到了 cleanup 不会处理,如果遇到的是 catch 并通过检查后,__gxx_personality_v0 返回 _URC_HANDLER_FOUND 表示已经在这一层找到了 handler。倘若经过多次栈回退,已经到了最高层函数依然没有找到 catch 那么 _Unwind_RaiseException 则 _Unwind_RaiseException 函数返回 _URC_END_OF_STACK。
清理阶段:_Unwind_RaiseException_Phase2 基于 Phase 1 找到的 handler 信息,从 this_context(初始位置)开始真正展开栈,把各层次对象析构掉(如果有cleanup ),并在目标 handler 处停止。如果在这个过程中出现问题,它会返回相应的错误码。正常情况下如果一切顺利返回_URC_INSTALL_CONTEXT,表示已找到 handler ,需要 uw_install_context 来切换程序上下文和实际执行流到 handler。
_Unwind_Reason_Code LIBGCC2_UNWIND_ATTRIBUTE |
可以看到上面 _Unwind_RaiseException 做了很多事情,为了方便具体是如何完成搜索和清理过程的,我们将代码拆开来看。
Phase 1
对于程序而言,运行到任一时刻也只有一套寄存器(这里称之为硬件寄存器)。之所以栈回溯能完成是因为模拟出了一套存储上下文信息的结构 cur_context。现在的调用链是 main->func1->func2->func3 ,在我们提到栈展开回溯函数调用 func3->func2->func1->main 的时候,自始至终改变的都是 cur_context 这样一套结构体。
栈回退的本质,找到当前函数(cur_context 在描述哪个帧,哪个就是当前函数)的返回地址。栈回退以 uw_update_context 和 uw_frame_state_for 函数共同完成。首先用 uw_frame_state_for 解析 FDE 和 CIE 生成 fs 结构体,接着调用 uw_update_context 函数,借助 fs 结构体和原 current 中的寄存器值更新出新的 CFA,再用 CFA 和 fs 更新出新的 current 中的寄存器值,包括函数返回地址。当遇到一个函数中存在 cleanup 或者 handler 时,就进入 personality 函数进行具体判断,直到找到 handler,至此第一阶段结束。
uw_update_context函数
uw_update_context 函数(定义在 libgcc/unwind-dw2.c)就是对 uw_update_context_1 的封装,最后又更新了 context->ra。
static void |
uw_update_context_1 函数用来恢复当前函数上下文。此处明确一个概念,假设当前的函数是 callee ,那么其调用者为 caller。此处说的恢复指的是将 callee 的上下文更新为 caller 的上下文。恢复上下文的原理其实很简单,就是根据一个基址寄存器加上一个偏移寻找到要恢复的值。这个基址寄存器被称为 CFA(Canonical Frame Address.标准栈帧地址)。
uw_update_context_1函数第一行代码是 struct _Unwind_Context orig_context = *context 将 context 做一个原始备份,存储在栈中局部变量 orig_context。看反汇编后的代码可以很直观的发现有备份操作。
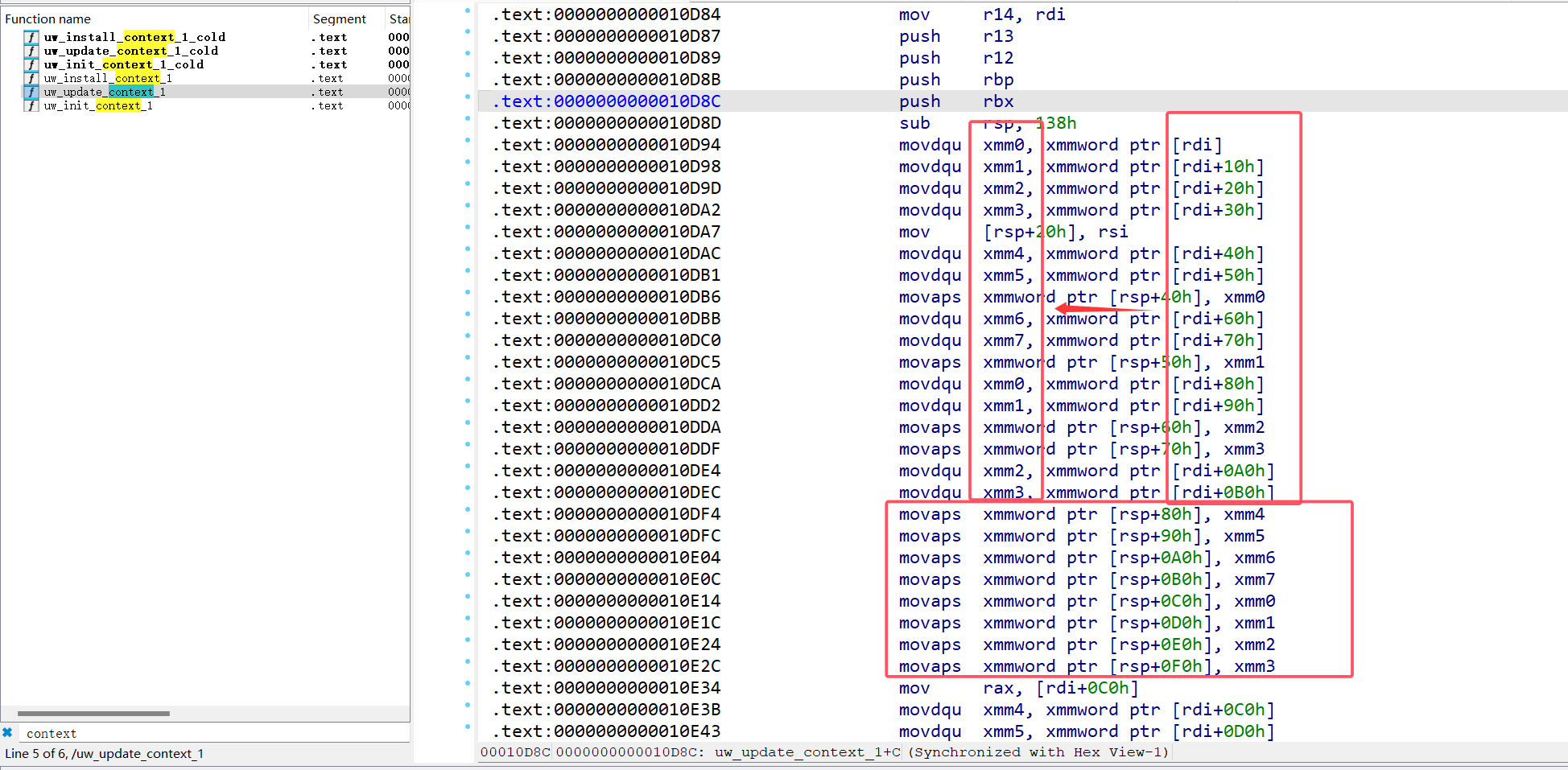
CFA 的生成代码如下,先根据 fs->regs.cfa_how 获取 CFA 的生成方式,以 CFA_REG_OFFSET 为例。 在 fs 结构体中获取 regs.cfa_reg 寄存器编号,通过 _Unwind_GetPtr 函数从 orig_context 结构体根据寄存器编号拿到寄存器的实际值,再加上 fs 结构体中 cfa_offset 字段得到最终 cfa。
switch (fs->regs.cfa_how) |
调试验证,下面是 fs 结构体各字段。
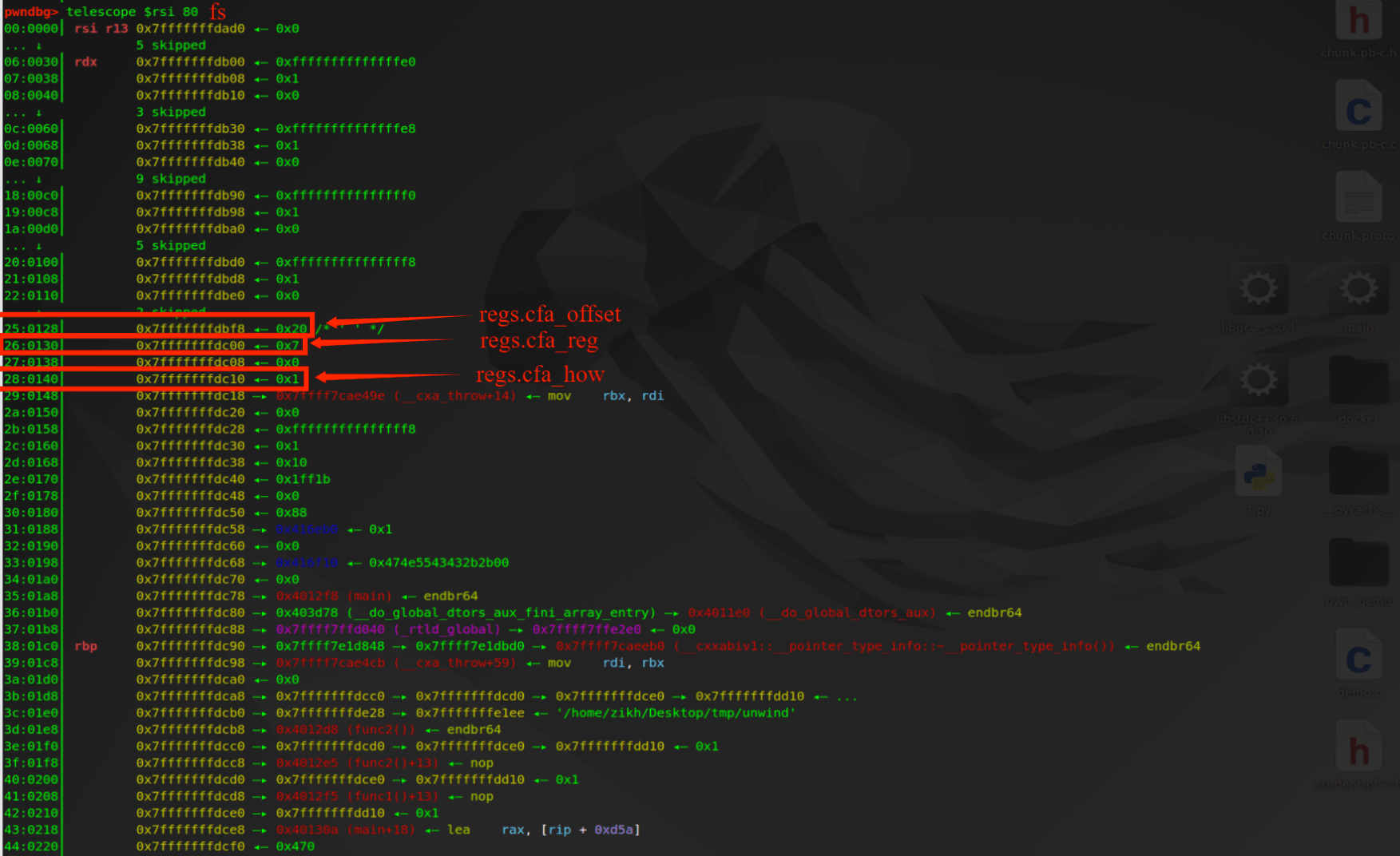
下面是 orig_context 结构体各字段(查看 context 结构体会计算出错)。因为 fs 结构体中 regs.cfa_reg 为 7,所以 _Unwind_GetPtr (&orig_context, fs->regs.cfa_reg) 的返回值应该是下图偏移 7 处经过解引用后的指针 0x7fffffffdca0。根据上图得知 fs 结构体中 regs.cfa_offset 为 0x20,因此最终的 cfa 应该是 0x7fffffffdca0+0x20=0x7fffffffdcc0。
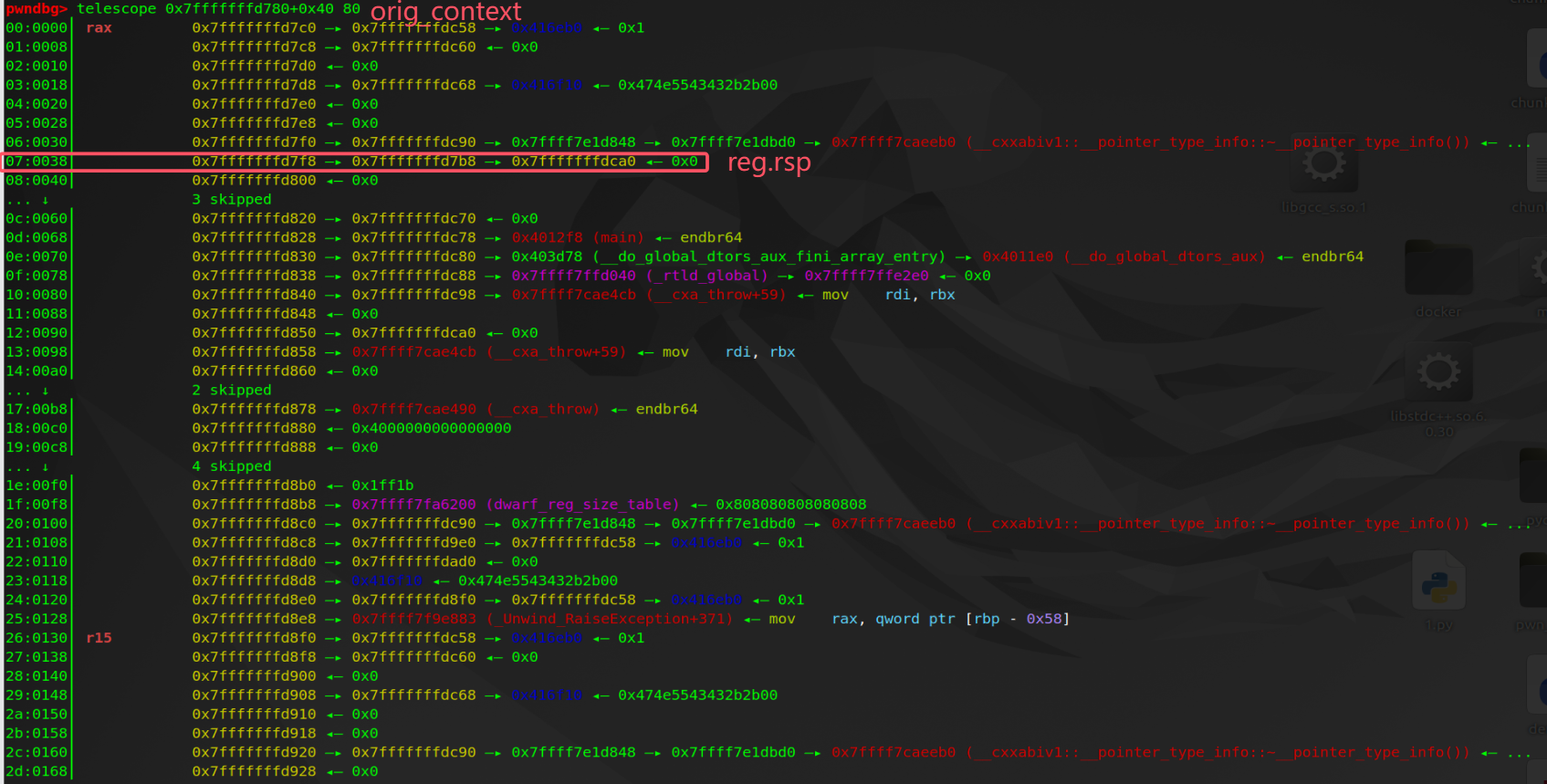
生成 CFA 的三条关键汇编代码和context->cfa = cfa 执行后 context 结构体如下。
<uw_update_context_1+382> mov rax, qword ptr [rsp + 0x20] |
生成 CFA 之后,开始恢复 cur_context 中寄存器。fs->regs.reg[i].how 描述了每个寄存器(reg 数组元素)在当前帧状态下的 保存方式。下面以 REG_SAVED_OFFSET 为例,其寄存器的值以偏移量的形式保存在栈帧中,具体的偏移量存储在 loc.offset 字段中,所以该寄存器值恢复就是用 CFA+loc.offset。
for (i = 0; i < __LIBGCC_DWARF_FRAME_REGISTERS__ + 1; ++i) |
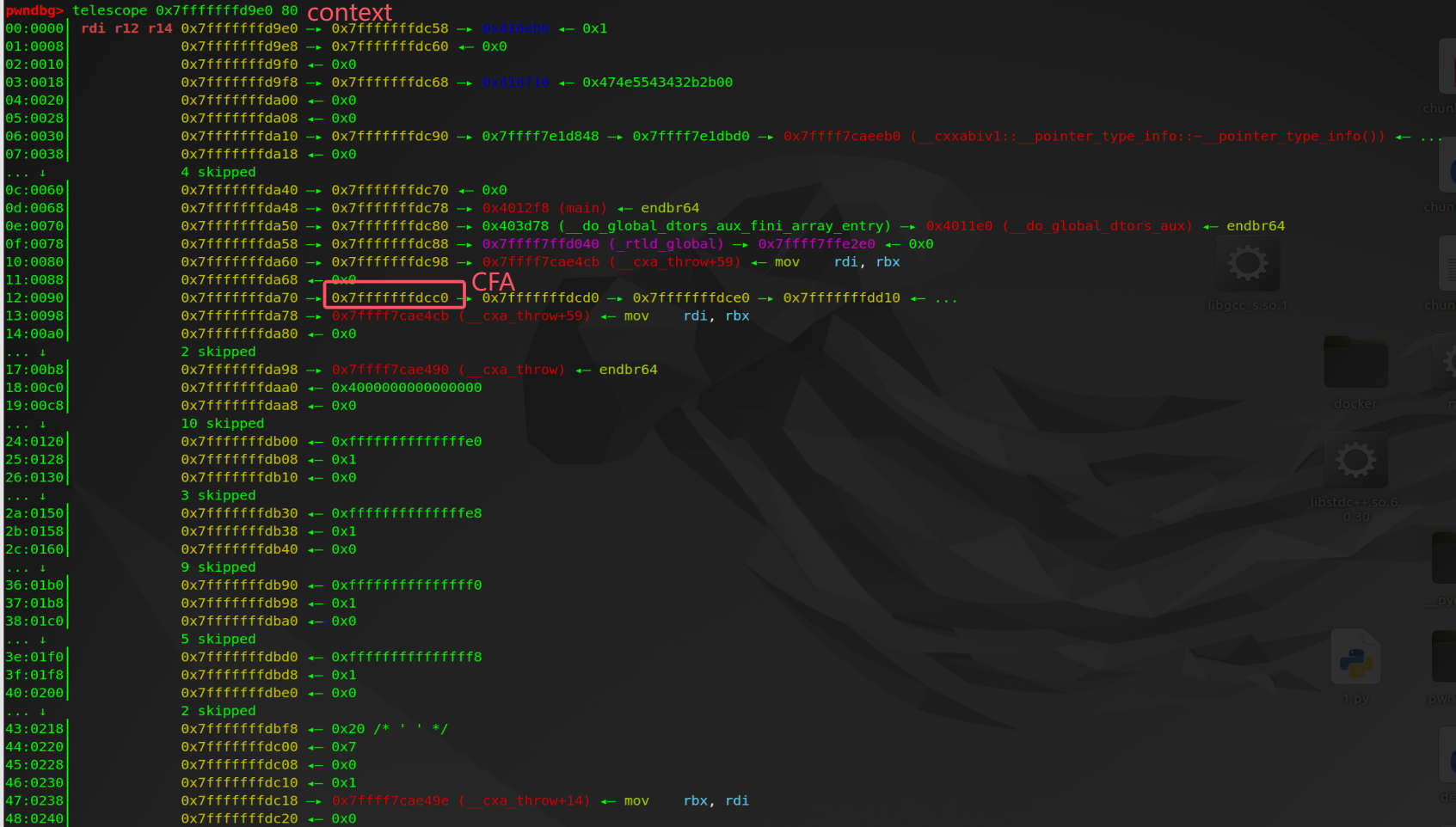
注意上面的代码,虽然遍历了所有寄存器,但是否恢复值取决于 fs->regs.reg[i].how,如果为 REG_UNSAVED 则意味着不会恢复该寄存器的值。以下面图片展示的 fs 结构体为例,来分析一下 RIP 寄存器最终的值。首先在偏移 0x20 的位置表示的是 RIP 的 reg结构中 loc 和 how字段。how 为 REG_SAVED_OFFSET,因此根据上面的计算方法 RIP= CFA + offset,这里的 offset 是 -8(0xfffffffffffffff8)。
上文提到 CFA 为 0x7fffffffdcc0,因此 RIP 实际应该还原成 0x7fffffffdcb8 指向的数据。下图为 uw_update_context_1 函数执行结束后,寄存器恢复后的值。在偏移为 0x10 的位置是 reg[RIP]。
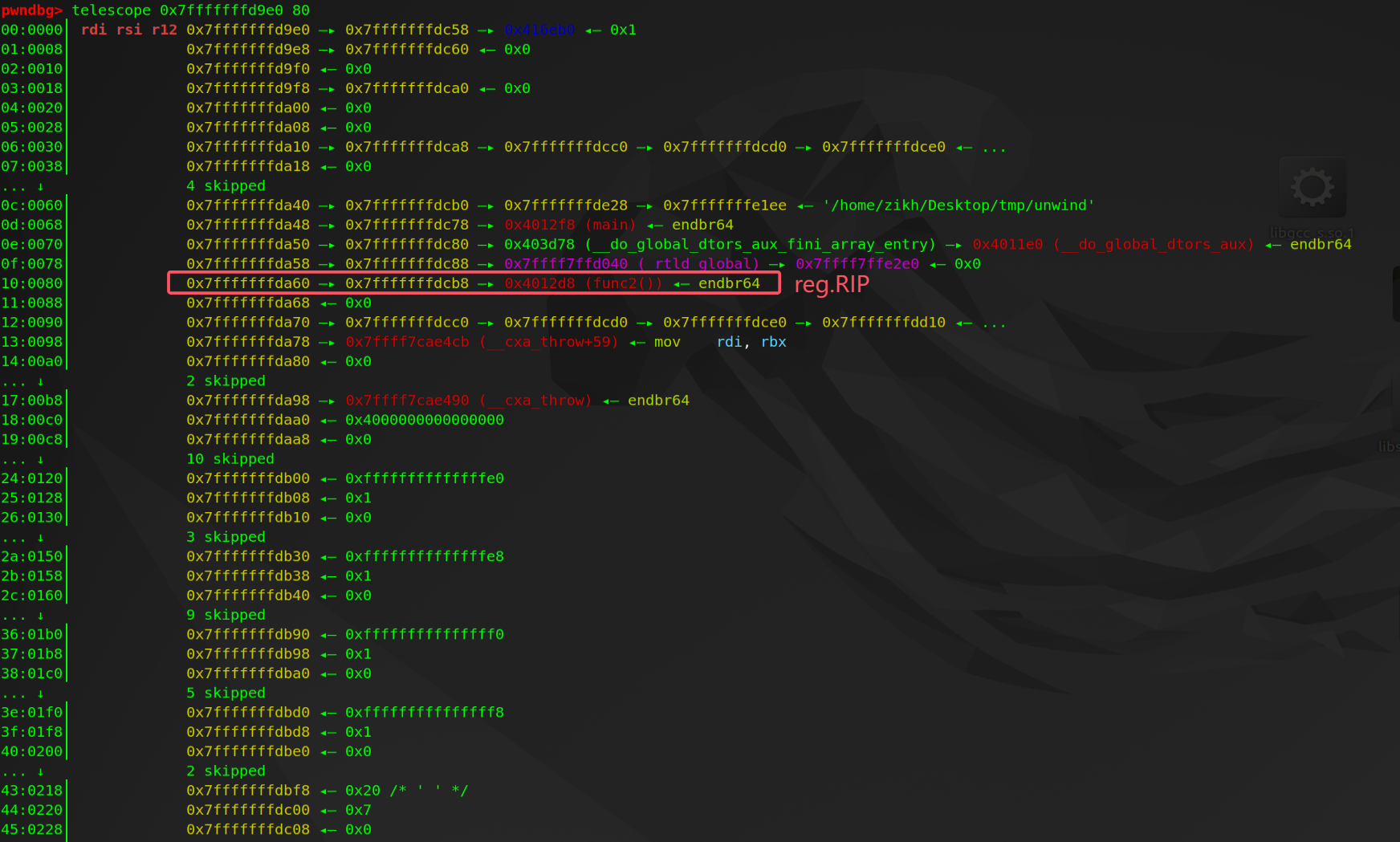
在 uw_update_context_1 执行后,通过 fs->retaddr_column 辅助确定当前帧的返回地址。retaddr_column 描述了返回地址所在的列,表示在寄存器保存状态中,哪个位置保存了返回地址。
ret_addr = _Unwind_GetPtr (context, fs->retaddr_column); |
在 _Unwind_GetPtr 中的调用是将 fs->retaddr_column 作为 index 从 context->reg[] 数组中取值。通过调试发现 fs->retaddr_column 一直是 0x10(reg[0x10] 是 RIP)。所以每一轮 uw_update_context 更新的 context->ra 都源于被刷新后的 context->reg[RIP]。
static inline void * |
调试如下,此时的 context->reg[0x10] 已经刷新,但还没有赋值给 context->ra。
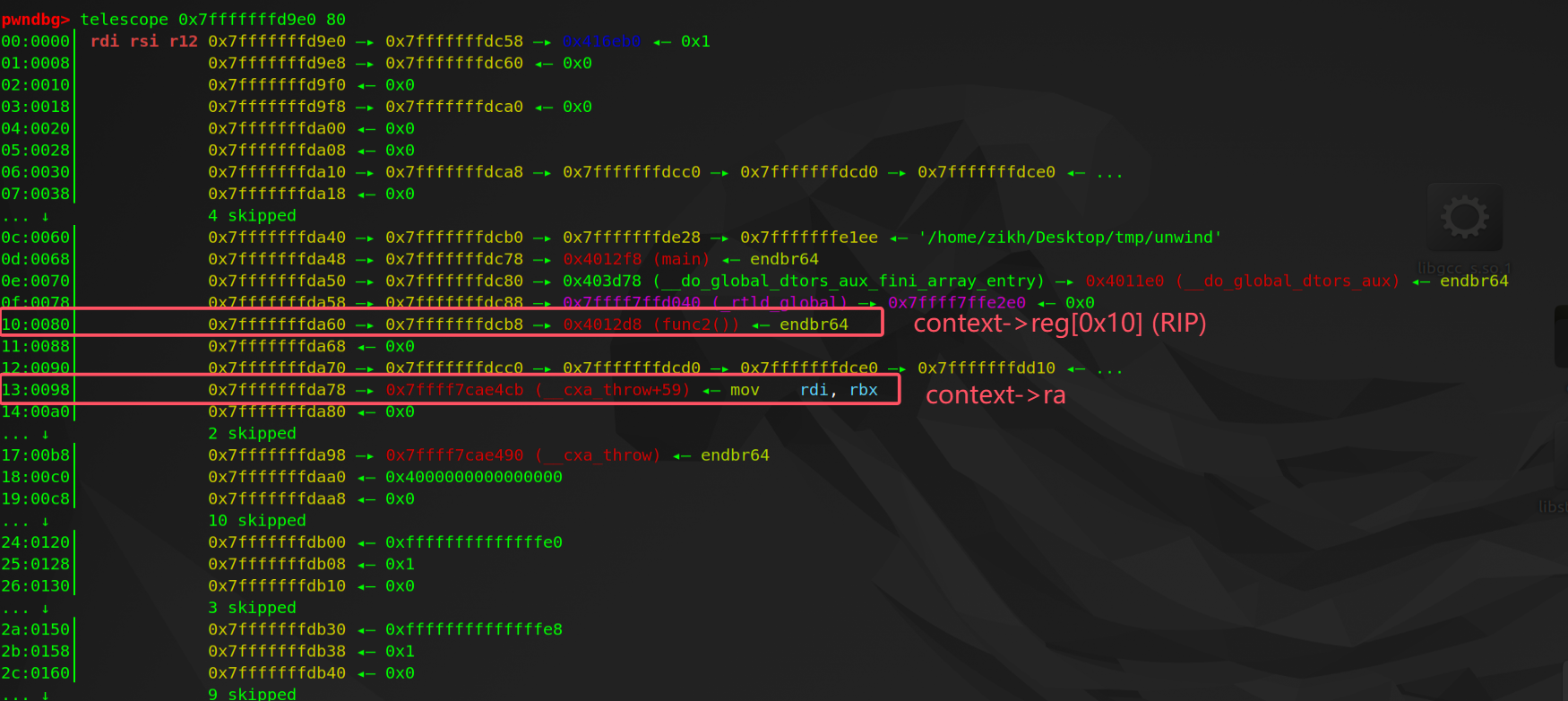
在这里已经能看到 context->reg[0x10] 经过一次解引用后更新给了 context->ra。

uw_frame_state_for函数
uw_frame_state_for 函数(定义在 libgcc/unwind-dw2.c)的核心功能是根据 DWARF 调试信息(CIE 和 FDE),解析栈帧的状态信息(在编译后就已经固定),对 fs 结构体进行赋值。 cur_context 的更新并不在该函数。该函数先通过 _Unwind_Find_FDE 查找 FDE ,再根据 FDE 找到 CIE 。对于这个函数我们只需要搞清楚程序是怎么判断出当前帧需要进入 persionaly 函数的即可,至于 FDE 和 CIE 是怎么被找到的以及 fs 结构体如何借助它们还原各字段信息,这些并不重要。因为 fs 结构体本身就是为了恢复 cur_context 服务的,关注如何恢复 cur_context 并向上级函数回溯才是本文要记录的。
static _Unwind_Reason_Code |
在 extract_cie_info 函数中获取了 CIE 的 Augmentation 字段,以遍历 Augmentation 的方式判断里面是否含有字符 P,如果存在 P 则表示当前函数中存在 cleanup 或者 catch,将 personality 函数指针赋值给 fs 结构体里面的 personality 字段。
static const unsigned char * |
使用命令 readelf --debug-dump=frames ./unwind 可以输出程序的 CIE 和 FDE。以 unwind 程序为例,下图展示了部分 CIE FDE。其中地址区间 0x401216-0x4012a5 与 0x4012f8-0x401371两个 FDE 对应都是偏移为 0x80 的 CIE 。该 CIE 的 Augmentation 字段含有 P,再通过 IDA 观察上面提到的两个区间,发现都包含 catch。
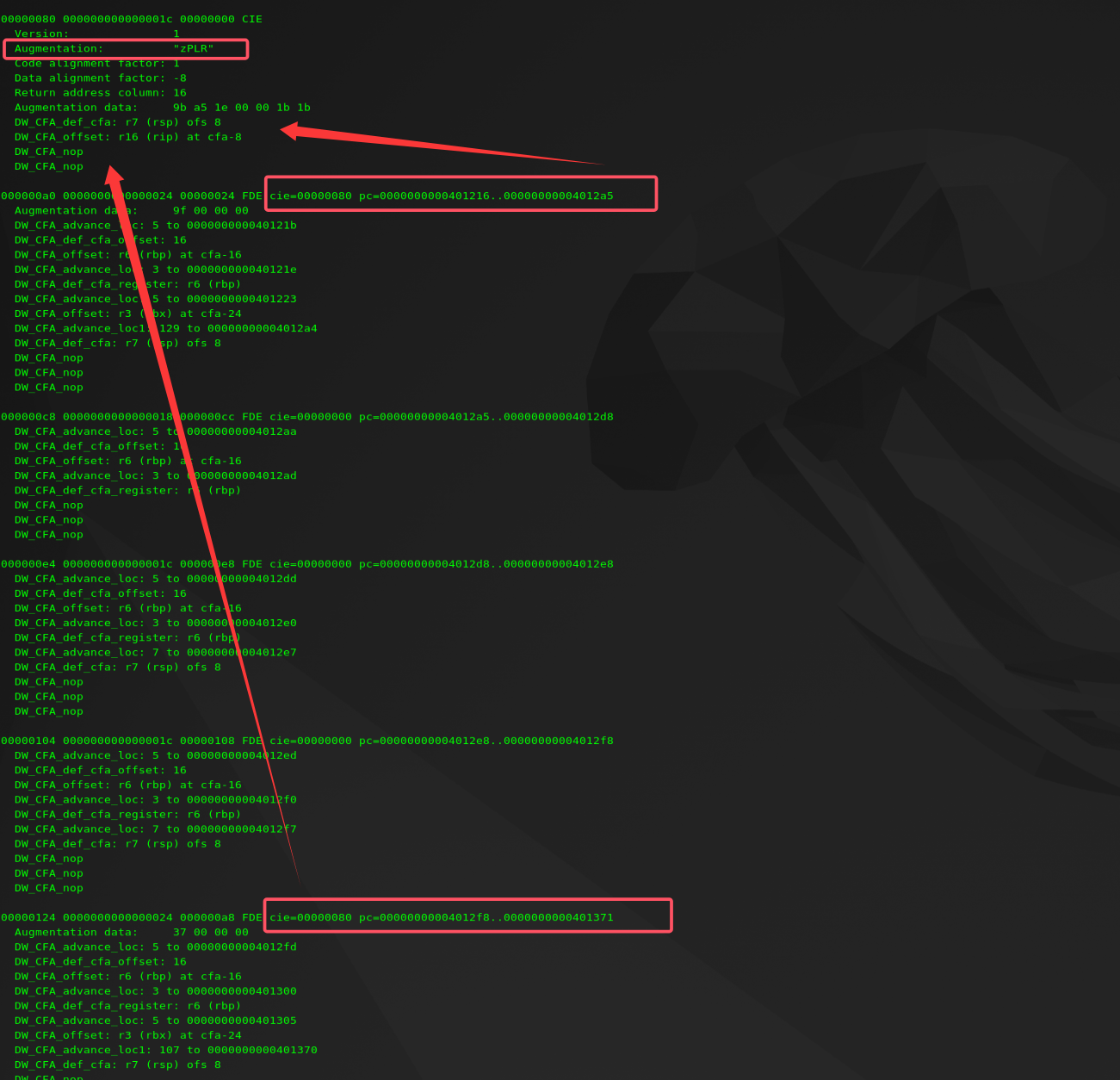
发现 CIE 中记录了 P 后,将 personality 函数指针赋值。回到 _Unwind_RaiseException 函数,在执行 uw_update_context 之前判断了 fs.personality 是否存在,如果存在的话,就调用 fs.personality 函数指针。
while (1) |
当要更新(但还未更新)的函数中存在 cleanup 和 handler(通过 FDE 找到 CIE ,判断 CIE 中的 Augmentation 字段来实现的)时,会在执行 uw_update_context 之前先进入 personality 函数。至此又到了文章开头讨论区间时分析的 __gxx_personality_v0 函数,简单来说,__gxx_personality_v0 通过解析 LSDA 中的数据执行不同的分支进行判断存在的是 cleanup 还是 handler。
解析.gcc_except_table中数据
.gcc_except_table 中存放的是 LSDA 。LSDA 由四部分组成,分别是 LSDA Header Call-Site Table Action Table Type Table,结构如下(图片来源于网络)。
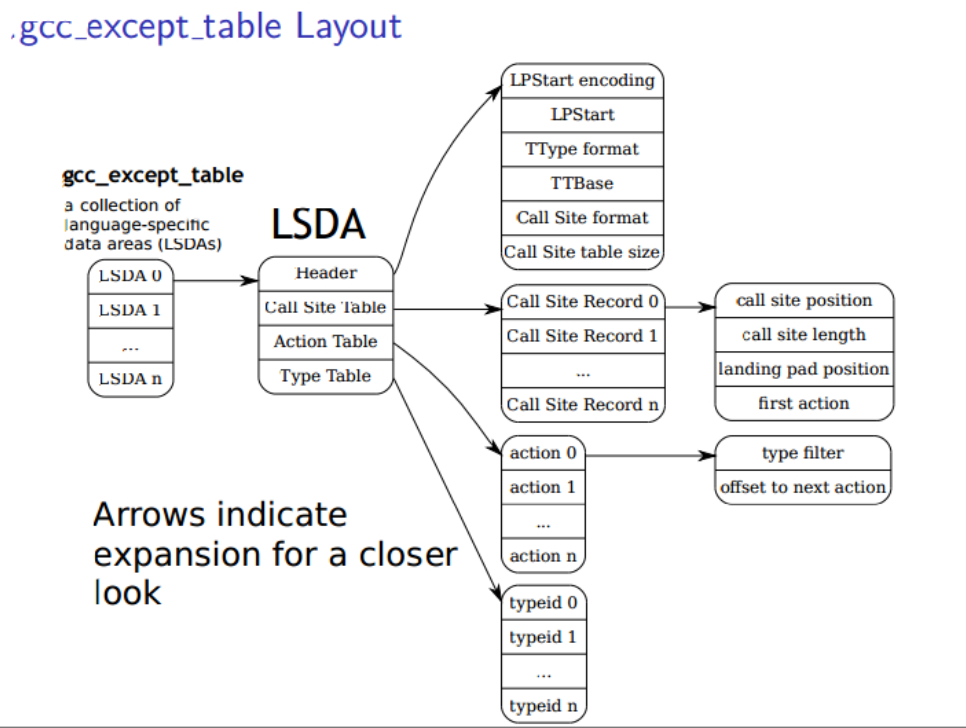
我没有从网上找到有很详细的资料对一组实际的 LSDA 原数据进行解析,尽管在这个 PDF 中44页开始有介绍 LSDA 中各字段,但不实际分析一个 LSDA 数据依然云里雾里。因此我分析了 parse_lsda_header 和 __gxx_personality_v0 里面的代码。下面来结合源码,让我们搞清楚这些原数据是怎么帮助 personality 函数工作的。
以上文编译的 unwind 程序为例,LSDA 原数据如下。
readelf -x .gcc_except_table ./unwind |
从 __gxx_personality_v0 函数开始看,其中有一行代码 p = parse_lsda_header (context, language_specific_data, &info);,在 parse_lsda_header 函数中对一些字段进行了解析,language_specific_data 就是 LSDA 的起始地址(0x402230)。
下面是 parse_lsda_header 源代码,第八行 lpstart_encoding = *p++; 从 LSDA 中取了一个字节赋值给变量 lpstart_encoding,它的含义是 Landing Pad 起始地址的编码方式。如果该值不是 0xff 那么会再读取数据,作为 info->LPStart(Landing Pad 起始地址)。但从例子的原始数据来看,读取的是 0xff,所以 info->LPStart 是调用 _Unwind_GetRegionStar 函数获得的。接着读取一个字节作为 info->ttype_encoding,它是 Type table 的编码方式。如果该值不是 0xff 那么 info->TType 再从原始数据读取一个 uleb128 值(0x19) 再加上当前指针(0x402233),也就是 0x40224C ,info->TType 代表 Type table 的起始地址。再读取一个字节(0x01)作为 info->call_site_encoding,它表示 call_site Table 的编码方式,最后再读取一个 uleb128 数据(0x11)加上当前指针(0x402235),也就是 0x402246,info->action_table 代表 action_table 的起始地址。
static const unsigned char * |
总结一下上面的代码,依次解析了 LSDA Header 中的 Landing Pad起始地址编码方式、Landing Pad起始地址、Type Table编码方式、Type Table起始偏移、Call-Site Table编码方式、Call-Site Table长度。注意:起始偏移指的是 LSDA 中原始数据该字段解析的值,而起始地址表示源码中已经将基地址指针 p 和偏移相加后的值。
根据上面分析得出, LSDA 原始数据中 LSDA Header 是 FF 9B 19 01 11。
| 字节 | 字段名称 | 值 | 含义 |
|---|---|---|---|
0xFF |
Landing Pad起始地址编码方式 | DW_EH_PE_omit |
Landing Pad 起始地址省略,需通过 _Unwind_GetRegionStart() 获取 |
0x9B |
Type Table 编码方式 | DW_EH_PE_sdata4 |
Type Table 的偏移量为 4 字节的有符号整数 |
0x19 |
Type Table起始偏移 | 0x19 |
Type Table起始偏移加上p指针为Type Table在LSDA中地址 |
0x01 |
Call-Site Table编码方式 | DW_EH_PE_uleb128 |
Call-Site Table 使用 ULEB128 编码。 |
0x11 |
Call-Site Table长度 | 0x11 |
Call-Site Table长度加上p指针,就可以定位到action table |
在 LSDA Header 之后的是 Call-Site Table,Call-Site Table 由多个 Call-Site Entry 组成,每个 Call-Site Entry 又由 cs_start cs_len cs_lp cs_action 四个字段组成。
p = read_encoded_value (0, info.call_site_encoding, p, &cs_start); |
在 call_site_encoding 中表示 Call-Site Table 里面的数据使用 ULEB128 编码,已知 Call-Site Table 的总长度为 0x11 字节,数据为 1c 05 23 01 30 05 00 00 57 14 72 00 84 01 05 00 00。下面分组中的 Entry 4 的 cs_start 为 84 01 的原因是 0x84 的控制位是 1,表示 ULEB128 编码还没有结束,需要继续读取下一个字节,尽管 84 01 表示的还是 0x84😅。
| Call-Site Entry | cs_start | cs_len | cs_lp | cs_action |
|---|---|---|---|---|
| Entry 1 | 1c | 05 | 23 | 01 |
| Entry 2 | 30 | 05 | 00 | 00 |
| Entry 3 | 57 | 14 | 72 | 00 |
| Entry 4 | 84 01 | 05 | 00 | 00 |
但需要注意的是 ip 指针如果落在了一组 Entry 中,那么就不会再解析后面几组 Entry了。指针如果不依次移动,如何找到 LSDA 中的 action table 呢?因为知道 Call-Site Table 的长度,而 action table 就在 Call-Site Table 之后。 具体代码为 action_record = info.action_table + cs_action - 1 记录了 action_table 的位置,从上面原始数据来看,第一组解析的 cs_action 为 1,因此 LSDA Header 中的 action_table(0x402246) 就作为 action_table 的起始地址。
下面用 p = action_record 直接跳过了剩余的 Call-Stie Entry,依次解析了两个 sleb128 编码数据作为 action table 中的字段 ar_filter ar_disp。当 ar_filter 为 0 代表当前函数存在的是 cleanup。
p = action_record; |
| ar_filter | ar_disp |
|---|---|
| 01 | c8 |
在本例中 ar_filter 为 1,那么会执行 catch_type = get_ttype_entry (&info, ar_filter) 函数。size_of_encoded_value (info->ttype_encoding) 的返回值为 4,因此这里最后的 i 为 4。但作为 read_encoded_value_with_base 函数的第三个参数,它将 info->TType(0x40224C) 减去了 4 字节。这里非常有意思,参考下图(来自 PDF 46页)发现 TTBase 指向的并不是 type table 的起始地址,必须要再减去一个 i。
static const std::type_info * |
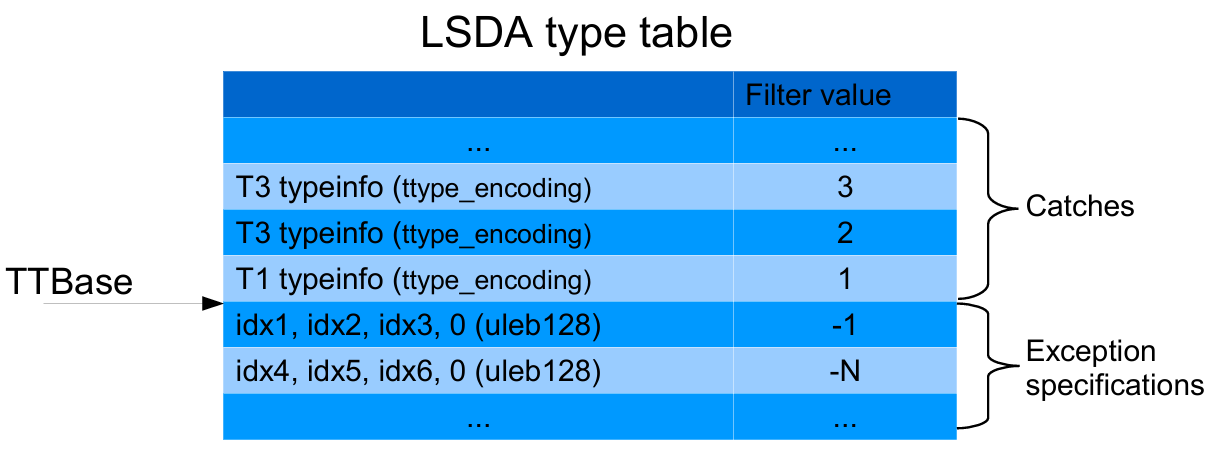
再看一下简易版的 read_encoded_value_with_base 函数,通过判断 info->ttype_encoding(0x9b) 的值,进入分支执行 result = u->s4,u->s4 表示从 u 指向的内存地址读取四字节数据,也就是上文提到的 info->TType - i => 0x40224C - 4 => type table真正的起始地址 0x402248 。从 LSDA 的原始数据来看 0x402248 指向的是 c81d0000 ,以小端序来读取,因此实际值为 0x1dc8。最后还有代码 result += ((encoding & 0x70) == DW_EH_PE_pcrel ? (_Unwind_Internal_Ptr) u : base); 也就是 val 为 0x1dc8+0x402248 = 0x404010。
static const unsigned char * |
用 IDA 查看地址 0x404010,发现是指向实际的 typeinfo 对象地址(_ZTIPKc),这是一个 std::type_info 实例,用于描述 const char* 类型。

有代码 get_adjusted_ptr(catch_type, throw_type,&thrown_ptr) ,再来看 get_adjusted_ptr 的源码。throw_type 指向抛出异常类型的 std::type_info 对象,而catch_type 指向 catch 块捕获类型的 std::type_info 对象。__do_catch 是一个成员函数,用于比较 throw_type(实际抛出的异常类型)和 catch_type 是否兼容。因为在 unwind 这个例子中 throw 和 catch的类型都是 const char *,所以这里 get_adjusted_ptr 会返回 true。该函数作用是判断抛出的异常类型是否能在 type_table 记录的异常类型信息中匹配。
static bool |
因此下面分支就会进入,将 saw_handler 赋值为 true,并将 found_type 赋值为 found_handler,表示在当前函数中找到了 handler。因为是搜索阶段,所以会进入分支 if (actions & _UA_SEARCH_PHASE) , foreign_exception 为 0(在 libstdc++-v3\libsupc++\unwind-cxx.h 文件,定义了 __GXX_INIT_PRIMARY_EXCEPTION_CLASS(c) c 宏) ,因此 save_caught_exception 会保存状态信息,避免 Phase 2 中再次解析 LSDA ,最后返回 _URC_HANDLER_FOUND。
if (! catch_type |
Phase 2
上文提到 personality 函数会返回 _URC_HANDLER_FOUND, 因此触发 break 跳出 uw_frame_state_for 和 uw_update_context 的循环,执行下面的代码。将找到 handler 时的 context->CFA 记录到 exc->praivate_2 中, phase2 栈回溯时再次遍历到此栈帧时则可以直接执行的 handler 并结束处理。通过 _Unwind_RaiseException_Phase2 和 uw_install_context (_Unwind_Resume和__cxa_begin_catch函数均未分析)完成栈回退并执行存在的 cleanup,最终执行 catch 中的代码。
exc->private_1 = 0; |
分析 _Unwind_RaiseException_Phase2 函数,整体逻辑仍然是一个 while 循环,里面用 uw_frame_state_for 和 uw_update_context 来栈回退。上文提到,在 Phase 1 结束后记录了存在 handler 函数的 CFA,通过代码 match_handler = (uw_identify_context (context) == exc->private_2 ? _UA_HANDLER_FRAME : 0); 判断 Phase 2 是否回溯到了有 handler 的那个函数。 match_handler 被赋值不同,会导致在调用 personality 函数时走的分支不同。
static _Unwind_Reason_Code |
当 match_handler 是 _UA_HANDLER_FRAME 则会在 personality 函数跳转至 install_context。首先进入 else 分支,因为 handler_switch_value 在跳转至 install_context 之前执行了 restore_caught_exception 恢复了 Phase 1 找到 handler 时的一些数据,依然是 unwind 的例子,这里 handler_switch_value 值为 1。
install_context: |
_Unwind_SetGR 函数通过下面代码,更新了 context->reg[0] 和 context->reg[1] 寄存器的值。_Unwind_SetIP 则将 landing_pad (landing_pad的生成方式是info.LPStart + cs_lp,指向catch的代码)更新成 context->ra。
ptr = (void *) (_Unwind_Internal_Ptr) context->reg[index]; |
personality 函数执行结束后,通过 break 跳出了栈回退的代码。至此 _Unwind_RaiseException_Phase2 函数也返回 _URC_INSTALL_CONTEXT。
uw_install_context 作为宏定义在 unwind-dw2.c 文件,最终改变执行流的是 __builtin_eh_return (offset, handler),通过 handler+offset 改变 PC 从而使执行流转到异常处理代码。
零零散散的补充
LSDA CIE FDE傻傻分不清
最开始看网上文章时,这三个分不清。
位置:
LSDA 位于 .gcc_except_table,而 CIE 和 FDE 都位于 .eh_frame。
作用:
LSDA 的数据辅助异常处理的捕获和类型匹配,而 CIE 和 FDE 主要用来辅助栈展开并辅助恢复 current_context 的上下文数据。
current和fs结构体分析及偏移量表格
current 的结构体类型定义在 libgcc/unwind-dw2.c
struct _Unwind_Context |
这些字段都是调试程序时分析出来的,不保证一定正确,并且一些字段在分析时没有注意,暂无记录。调试的程序是 x64 架构。
| 字段 | 含义 | 偏移 |
|---|---|---|
| reg.rax\reg.rbx\reg.rcx\reg.rdx \reg.rsi\reg.rdi\reg.rbp\reg.rsp \reg.r8\reg.r9\reg.r10\reg.r11 reg.r12\reg.r13\reg.r14\reg.r15\reg.rip |
reg数组里面的成员依次是这17个寄存器 | reg.rax偏移是0 reg.rbx偏移是0x8 reg.rcx偏移是0x10 以此类推,最后的reg.rip偏移是0x80 |
| reg.? | reg数组有18个单元,最后一个作用未知 | reg.?偏移是0x88 |
| cfa | Canonical Frame Address,标准帧地址 | 0x90 |
| ra | 当前帧的返回地址 | 0x98 |
| lsda | Language-Specific Data Area,语言特定数据区 | 0xa0 |
| bases | 0xa8 | |
| … | … | … |
fs 的结构体类型定义在 libgcc/unwind-dw2.h
typedef struct |
| 字段 | 含义 | 偏移 |
|---|---|---|
| regs.reg[rax].loc | reg的第1个寄存器是rax,loc表示恢复寄存器值的必要数据 | 0 |
| regs.reg[rax].how | reg的第1个寄存器是rax,how表示寄存器保存方式 | 0x8 |
| regs.reg[rbx].loc | reg的第2个寄存器是rbx,loc表示恢复寄存器值的必要数据 | 0x10 |
| regs.reg[rbx].how | reg的第2个寄存器是rbx,how表示寄存器保存方式 | 0x18 |
| … | 寄存器顺序和_Unwind_Context结构体中的reg成员一样,偏移也以此类推 | … |
| … | … | … |
| regs.reg[rip].loc | reg的第17个寄存器是rax,loc表示恢复寄存器值的必要数据 | 0x100 |
| regs.reg[rip].how | reg的第17个寄存器是rax,how表示寄存器保存方式 | 0x108 |
| regs.reg[?].loc | 这里reg数组中的单元也比寄存器数量多1,因此不确定多出来的这个内存单元作用 | 0x110 |
| regs.reg[?].how | … | 0x118 |
| regs.prev | 指向前一个 frame_state_reg_info 结构体的指针 | 0x120 |
| regs.cfa_offset | CFA根据cfa_reg指定的寄存器加上cfa+offset得到(cfa_how为CFA_REG_OFFSET时使用) | 0x128 |
| regs.cfa_reg | CFA根据cfa_reg指定的寄存器加上cfa+offset得到(cfa_how为CFA_REG_OFFSET时使用) | 0x130 |
| regs.cfa_exp | CFA地址表达式,描述了如何计算出栈帧的基准地址(cfa_how为CFA_EXP时使用) | 0x138 |
| regs.cfa_how | CFA的生成方式 | 0x140 |
| pc | 记录下一条即将执行的指令地址 | 0x148 |
| personality | 指向异常处理的个性化函数 | 0x150 |
| data_align | 数据对齐 | 0x158 |
| code_align | 代码对齐 | 0x160 |
| retaddr_column | 表示返回地址的列号,需要根据该字段恢复返回地址 | 0x168 |
| fde_encoding | FDE的编码方式 | 0x170 |
| lsda_encoding | LSDA的编码方式 | 0x171 |
| saw_z | 未知 | 0x172 |
| signal_frame | 信号帧标志位 | 0x173 |
| eh_ptr | 指向异常处理指针 | 0x178 |
尾声
这篇文章的编写零零散散持续了小一个月,用的很零碎的时间就导致了关联性比较差,各位如果仔细阅读也能发现文章的逻辑有点怪怪的。C++异常处理是一个有趣的过程,它在运行时可以跨越堆栈,最终直接跳转至异常处理的代码。这个原理引起了我的兴趣,因此我花费了不少时间来探究。但是否真的有实际场景能用上这篇文章作为参考,我无法确定。因此这篇文章读起来可能没有什么帮助,编写的初衷也仅仅是我探究完原理的记录而已。至于文章的段落逻辑比较怪,是因为编写跨度拉的太长,编写这篇文章的兴趣已经消退了不少,后面就不打算再写了。
实际上 uw_install_context_1 _Unwind_Resume 函数分析、 FDE CIE 解析以及整个 throw 的调用流程图我原本都是打算写的,不过最后还是决定鸽了😥。后面打算看看 CHOP(Catch Handler Oriented Programming),也就是关于C++异常处理来利用溢出漏洞,但不一定会再更新到这篇博客上了🤤。
参考文章
C++异常处理源码与安全性分析_异常personal routine-CSDN博客